
민프
[AI] Human Pose Estimation - 1. 2D HPE(Human Pose Estimation) 이란? 본문
Human Pose Estimation이란?
Human Pose Estimation이란 직역하면 '사람의 자세를 추정'이라고 합니다.
즉, 영상/이미지 내에서 사람의 자세, 관절 또는 부위를 예측하는 것이 목적입니다.
Human Pose Estimation 사용분야
Human Pose Estimation의 사용분야는 사람의 포즈를 가지고 할 수 있는 모든 분야에 사용할 수 있습니다.
예를 들어서) 아래 사진을 보면 스쿼트를 할 때 바른 자세를 어떻게 하면 좋을지 텍스트로 나와있는 것을 볼 수 있습니다.
여기에서 Human Pose Estimation관련 모델들을 사용하여 자세를 파악 후 어디가 잘못되어있는지 알려줄 수 있게 사용할 수 있겠죠
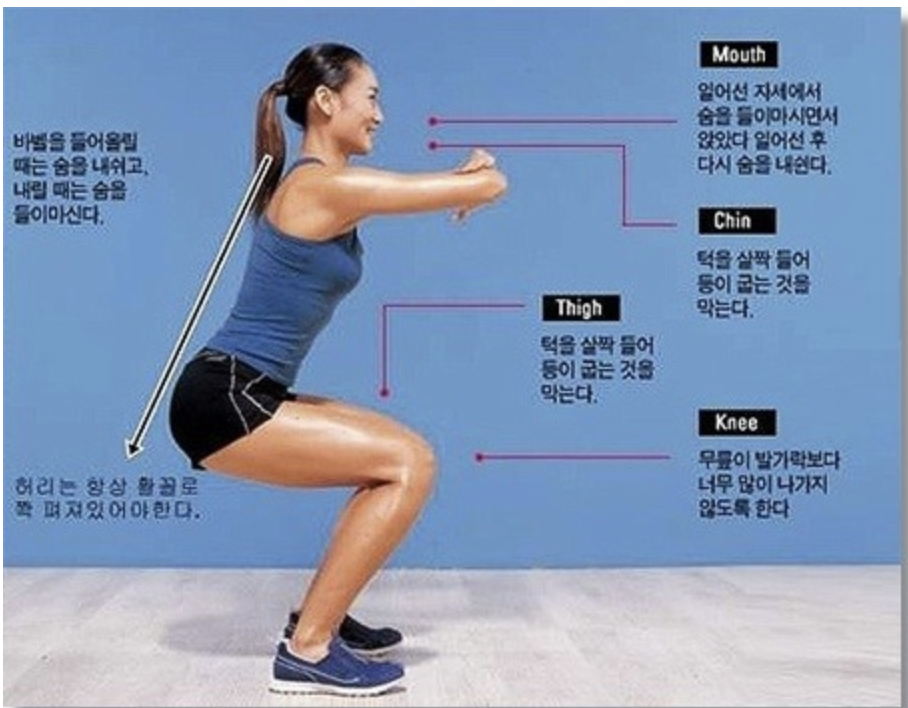
Human Pose Estimation 기술동향
그럼 이 HPE 모델들은 어떻게 관절의 위치를 찾게 되었는지 알아보겠습니다.
알아보기전에 간단하게 HPE에 관련 된 용어 정리를 해보겠습니다.
- Part(joint, key point) : 관절
- Limb(part pair, part connection) : 두 관절 사이 연결
휴먼 포즈 추정 문제란?
- 정의
- RGB영상 OR 거리(Depth) 영상, 사진으로부터 주요 신체 부위(Joint)의 위치를 찾는 문제입니다.
실제 사람의 관절과 관련 된 데이터를 보면 전체 230개 joint가 있다고 합니다.
근데 230개 전체를 다루지는 못하고 현재는 15~20개 정도의 joint를 정의하고 있습니다.
- RGB영상 OR 거리(Depth) 영상, 사진으로부터 주요 신체 부위(Joint)의 위치를 찾는 문제입니다.
- 어려운 문제
- 논문에서 보면 여러 인식에 대한 어려운 상황이 있지만 5가지로 좁혀보았습니다
- Self and External Occlusion
- 나의 신체부위가 다른 사물이나 사람에 의해서 가려지는 현상
- Arms and Legs Foreshortening
- 카메라의 위치에 따라서 관절을 볼 수 없는 현상
- Varying Illumination
- 그림자가 지어져서 관절을 파악하기 어려운 현상
- Clothing Variations
- 옷 때문에 관절을 제대로 파악하기 어려운 현상
- Motion Blur
- 영상 퀄리티가 좋지 않으면 Blur효과가 나타나서 관절을 파악하기 어려운 현상
- Self and External Occlusion
- 논문에서 보면 여러 인식에 대한 어려운 상황이 있지만 5가지로 좁혀보았습니다
위 문제들에 대한 접근 방법으로는 2가지가 있습니다.
- Marker
- 그림 (a)와 같은 스튜디오 환경에서 영화, 게임, AR/VR등 특수효과에 주로 사용되는 Marker 기반 Motion Capture System: 특수 마커(Marker) 부착 및 센싱 기반의 신체 joint 위치 추정기술이 있습니다.
- 이 방법은 비용이 비싸고, 특수 장비가 있어야하는 환경의 제약성이 크다는 단점이 존재합니다.
- Markerless
- 그림 (b)와 같이 앞으로 우리가 알아볼 RGB카메라 또는 Depth 카메라를 이용해 마커 없이 신체 joint 위치를 추정하는 기술입니다.
Maker System과 달리 비용이 저렴하여서 일반 환경에서 다양한 응용에 사용 가능합니다.
- 그림 (b)와 같이 앞으로 우리가 알아볼 RGB카메라 또는 Depth 카메라를 이용해 마커 없이 신체 joint 위치를 추정하는 기술입니다.


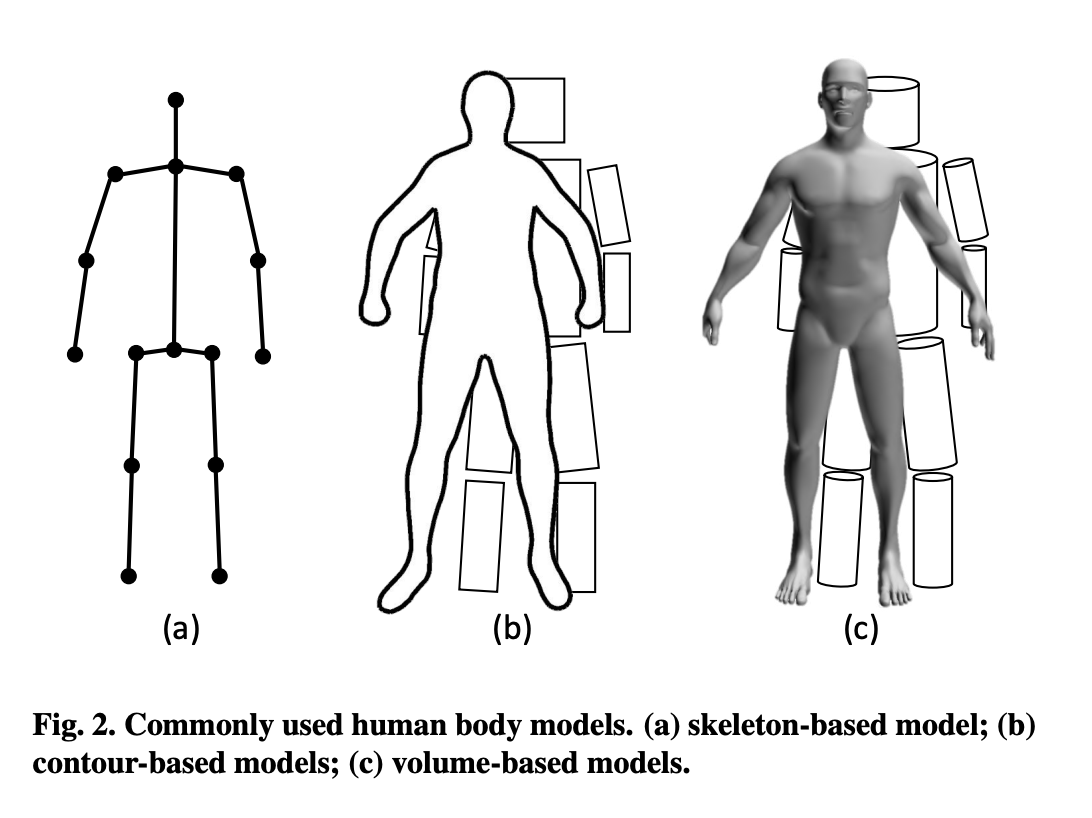
Human Body Models - 어떻게 관절의 위치를 찾았을까?
- Contour-based model
- 1970년대, Standford와 SRI에서 아래 왼쪽 그림과 같이 '모든 객체는 단순한 기하학적 형태로 표현 가능하다'라는 개념을 제안하여 등장하였고,
2000년대, 인터넷과 디지털 카메라 등 기술의 발전과 더불어 사람 모델링 연구의 발전으로 성능이 좋아졌지만 여전히 성능은 좋지 않았습니다.
- 1970년대, Standford와 SRI에서 아래 왼쪽 그림과 같이 '모든 객체는 단순한 기하학적 형태로 표현 가능하다'라는 개념을 제안하여 등장하였고,
- Skeleton-based model
- 신체 골격 구조를 구성하는 관절(joint, key point)로 이루어진 모델
- 2D pose에서는 (x,y)
3D pose에서는 (x,y,z) 좌표로 사용됩니다.
- Volume-based model
- 3D Body Shape 및 3D pose 추정에 일반적으로 활용되고 있고,
3D mesh 데이터를 활용하여 모델링하게 됩니다.
- 3D Body Shape 및 3D pose 추정에 일반적으로 활용되고 있고,
Human Pose Estimation 모델 분류
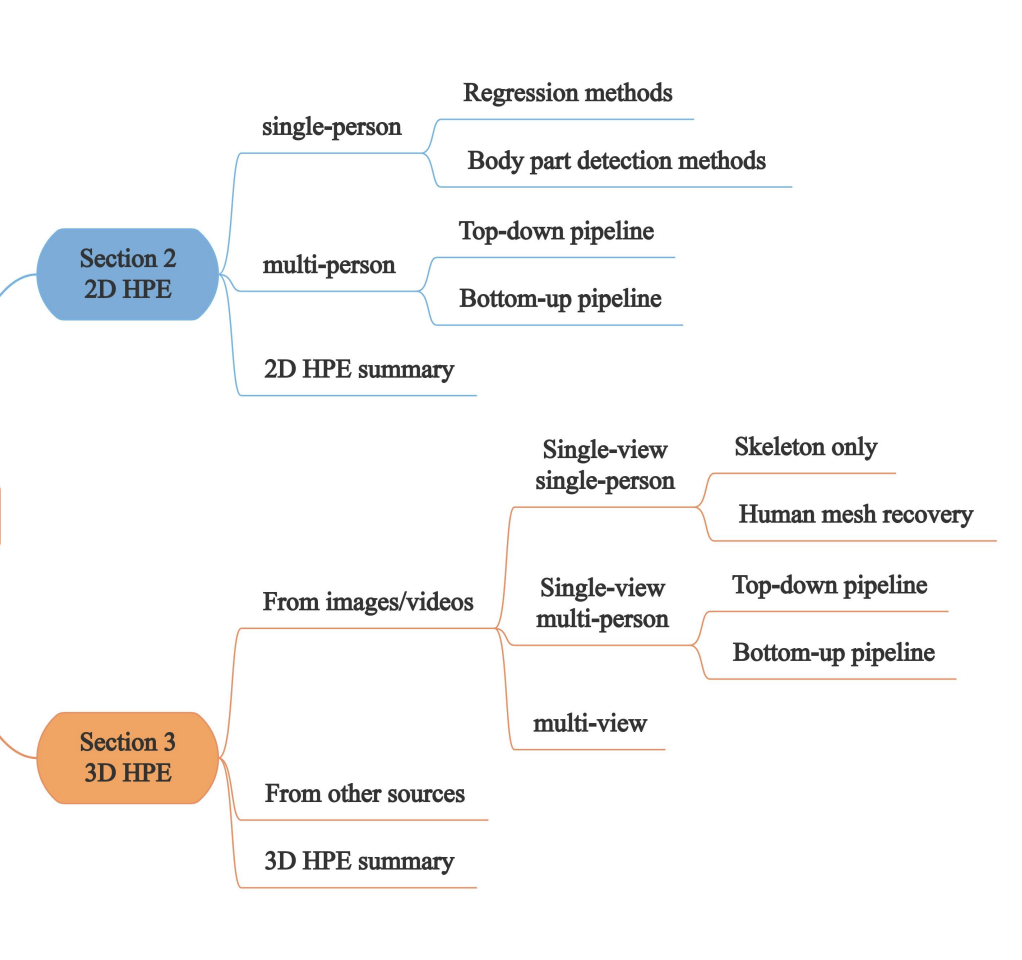
논문에 의하면 위 사진과 같이 분류가 되어있다고 합니다.
먼저 2D, 3D 간단하게 차이를 알아보겠습니다.
2D Human pose estimation?
2D Human pose estimation 방법은 주로 2D 이미지에서 사람의 관절 위치를 추정하는 것에 중점을 둡니다. 즉, 이미지 평면에서 관절의 x, y 좌표를 예측합니다.
x,y 좌표를 예측함으로써 깊이 정보가 없습니다. 따라서 관절의 위치를 평면에서만 예측하게 됩니다.
관련 모델로는 MoveNet, OpenPose, CPN, AlphaPose, HRNet, DeepPose 등이 있습니다.
3D Human pose estimation?
3D Human pose estimation 방법은 3D 공간에서 사람의 관절 위치를 추정하는 것을 목표로 합니다. 즉, x, y, z 좌표를 사용하여 관절의 위치를 예측하려고 합니다.
z좌표가 생김으로인해 관절 위치에 대한 깊이 정보를 가지며, 관절의 위치가 3D 공간에서 어디에 있는지 2D보다 더 정확하게 파악할 수 있습니다.
관련 모델로는 3D PoseNet, Volumetric Approach, Multi-View Approach, Graph-based Approach, IKNet (Inverse Kinematics Network) 등이 있습니다.
2D, 3D 복잡성
아무래도 x, y, z축으로 하나의 차원이 더 생김으로써 3D가 더 복잡하다
데이터셋을 구하는 것이나 만들때에도
2D Human Datasets는 쉽게 구하고 비교적 쉽게 라벨링을 하여서 데이터셋을 구축할 수 있는 반면에
3D Human Datasets은 구하기가 어렵고, 자체적으로 라벨링 하기도 어렵고, 라벨링을 하더라도 정확하지 않습니다.
2D, 3D 현재 연구 상황
이 부분은 확실하지는 않지만 서울대학교 이경무 교수님 교육 영상에 대한 부분을 캡쳐해보았는데
현재 연구 상황은 아래와 같다고 합니다.
확실히 역사가 오래될수록 연구 결과가 좋다는 것을 확인할 수 있습니다.

2D Human pose estimation
이제 HPE와 역사를 간단하게 알아보았으니 본격적으로 2D HPE에 대해서 설명해드리겠습니다.
Single Person Pose estimation
- 정의 : 입력 이미지 내 사람 한 명만 존재하는 경우를 의미합니다.
- Direct regression - (c)사진 : 관절 별 좌표를 예측
- Heatmap based estimation - (b)사진 : 특정 관절이 존재할 만 한 곳을 Heatmap 형태로 출력

Single Person 2D Pose estimation - 1. DeepPose Model
- 소개

동작원리를 알아보기 위해서 Pose Estimation에서 최초로 DNN을 적용한 모델인 Deep Pose의 논문을 참고하였습니다.
DeepPose는 2014년 IEEE Conference on Computer Vision and Patteren Recognition에서 발표되었고,
DeepPose는 최초로 DNN 기반의 HPE 방법을 제안하였고, DNN을 적용하여 SOTA를 달성하였습니다.
(*SOTA는 State-of-the-art의 약자로 현재 최고 수준의 결과를 의미한다.)
당시 딥러닝을 주로 Classification task에만 사용하였는 데 Regression task에서도 훌륭히 적용할 수 있음을 증명했습니다.
- DeepPose 동작 과정
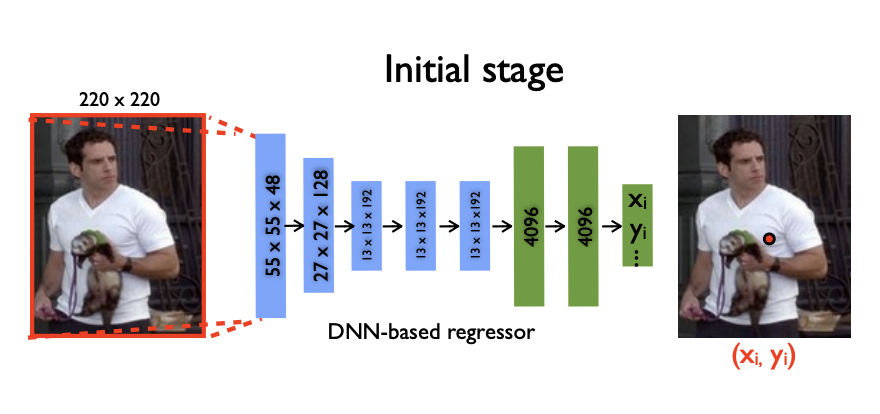
- Initial Stage or Stage 1
- 입력 이미지를 AlexNet 기반의 CNN-regressore에 통과시켜서 각 관절의 대략적인 위치를 파악합니다.
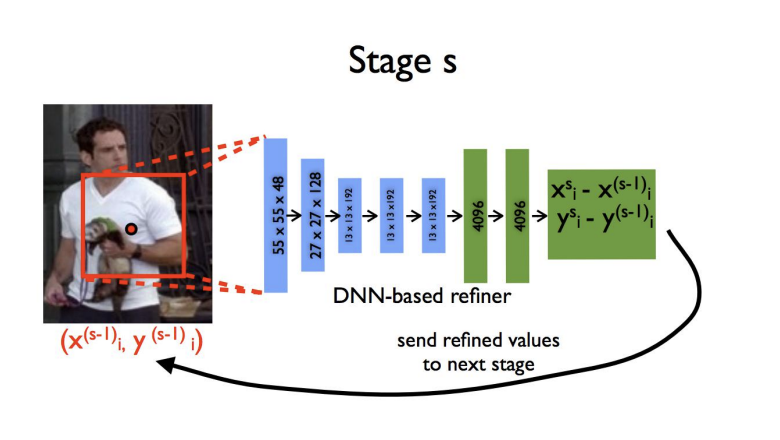
- Stage S or Stage 2
- Stage 1의 관절 좌표값에 가서 주위를 Crop 후에 다시 CNN에 넣어서 더 정확한 x, y 좌표값을 찾도록 하였습니다.
- Initial Stage or Stage 1
- DeepPose 결과는?
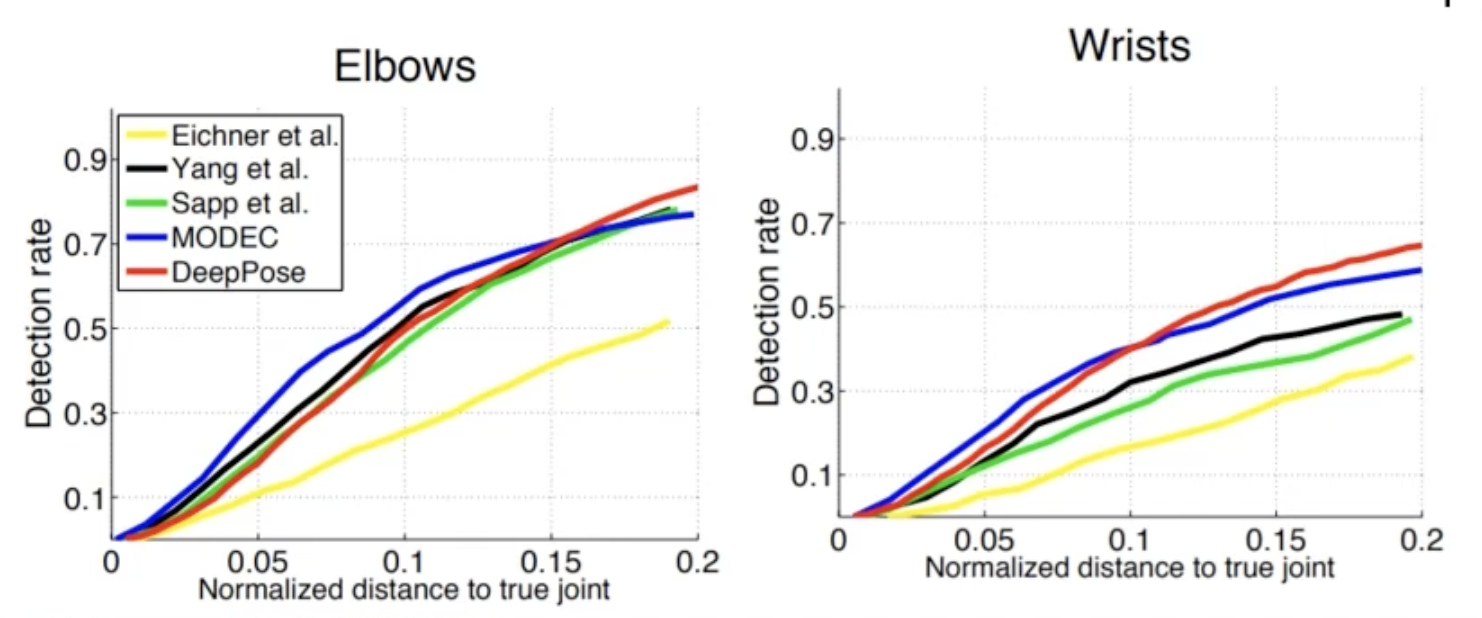
- 아래 사진을 보면 기존에 클래식한 방법들과 비교해서 크게 성능이 나아지지 않았다는 것을 확인할 수 있습니다.
이유로는 x, y 포지션을 직접적으로 나타내려고 하는 부분이 문제였습니다.
너무 정확한 값을 추측하려고 하니깐 Network에서 과부하가 생긴 것이었습니다.
- 아래 사진을 보면 기존에 클래식한 방법들과 비교해서 크게 성능이 나아지지 않았다는 것을 확인할 수 있습니다.
- DeepPose 문제점에 대한 대안은?
- HeatMap
- 아래 왼쪽 뉴욕 대학에서 나온 논문에 의하면
좌표값으로 인한 정확도 부족 현상이 공간적 위치 정확도의 한계 때문에 발생한다고 설명하고 있습니다.
이러한 문제를 해결하기 위해, 저자들은 공간적 정확도를 향상시키면서도 계산 오버헤드를 크게 증가시키지 않는
오른쪽 사진과 같은 ConvNet(CNN) 아키텍처를 제안합니다.
쉽게 말해 좌표대신 joint가 나타날 확률(heatmap)을 추정함으로써 정확도를 향상 시킨다는 것 입니다.
- 아래 왼쪽 뉴욕 대학에서 나온 논문에 의하면
- HeatMap


아래 왼쪽 사진에서 (b)를 보면 heatmap으로 나타낸 것을 확인할 수 있는데
저렇게 joint가 있을만한 곳의 확률이 높으면 빨간색 아니면 노란색, 파란색으로 표시가 됨으로써 마지막으로는 그 선을 이어서 나타내줍니다.
결과적으로 아래 오른쪽 사진을 보시면 이전 모델들과 비교해서 1.5배 이상 성능이 좋아진 것을 확인하실 수 있습니다.
- 한계점
- Context(맥락), Receptive field(지역적인 정보), local & global feature
- 여전히 이러한 방식에는 신체 자체가 갖는 정보(신체의 구조적 정보), 맥락(context)를 사용하지 못하는 한계점이 존재하였습니다.
쉽게 말해 왼쪽 한 조각의 사진만으로는 이 부분이 어떤 것을 의미하는지 알 수 없지만
오른쪽 사진을 보면 전체 사진(Context)에서 해당하는 부위가 어떤 부위인지 알 수 있는 것 처럼
맥락(Context) 정보를 사용하게 된다면 정확도를 올릴 수 있을 것이라고 판단하였다. - 이러한 한계점으로 인해 CPM(Convolutional Pose Machines)가 나오게 되었습니다.
CPM은 지역적인 정보(receptive field)를 local한 영역에서 global한 영역으로 확대하여 다른 부위와의 관계를 고려한 모델이다.
- 여전히 이러한 방식에는 신체 자체가 갖는 정보(신체의 구조적 정보), 맥락(context)를 사용하지 못하는 한계점이 존재하였습니다.
- Context(맥락), Receptive field(지역적인 정보), local & global feature


Single Person 2D Pose estimation - 2. CPM (Convolutional Pose Machines)
- 등장배경
- CPM은 2016년에 논문에 등재 되었고, 등장배경은 아래 논문에서 나와있듯
Convolutional Pose Machines (CPM)은 인간의 자세 추정에 대한 정확도를 향상시키기 위해 도입되었습니다.
기존의 방법들은 공간적 관계와 복잡한 형태를 학습하는 데 어려움이 있었고, 이를 해결하기 위해 CPM이 개발되었고,
CPM은 여러 단계의 학습을 통해 각 부위의 위치를 점점 더 정확하게 추정할 수 있습니다. - Receptive field를 통해 신체 구조 정보를 활용하고, Stage를 반복하여 추출한 heatmap의 context 정보를 활용하여 더 정확하게 관절의 위치를 찾을 수 있습니다.
- CPM은 2016년에 논문에 등재 되었고, 등장배경은 아래 논문에서 나와있듯


- 동작원리
- 아래 사진을 참고하며 간단하게 말하자면 순차적으로 Receptive field를 키우고 Context정보를 이용하여서 Joint 추정의 정확도를 높힐 수 있는 동작 입니다.
- Stage 1
- Conv Layer를 거쳐서 Receptive field를 키우고 Convolution 연산을 통해 나온 heatmap을 관절 수 만큼 예측하여, heatmap ground truth loss를 계산합니다.
- Stage 2
- State2에서는 Stage1에서의 결과값인 context feature와 입력 이미지를 마찬가지로 Conv Layer를 거쳐서 Receptive field를 키우고 같은 연산을 반복합니다.
이렇게 되면 Receptive field가 점점 커지면서 다른 관절들도 파악할 수 있게 될 수 있게 됩니다.
- State2에서는 Stage1에서의 결과값인 context feature와 입력 이미지를 마찬가지로 Conv Layer를 거쳐서 Receptive field를 키우고 같은 연산을 반복합니다.
- ~ Stage 6
- Stage 6번째까지 같은 네트워크 구조를 반복하여 연산을 진행하고, 총 손실 합을 줄이는 방향으로 학습이 진행되게 됩니다.
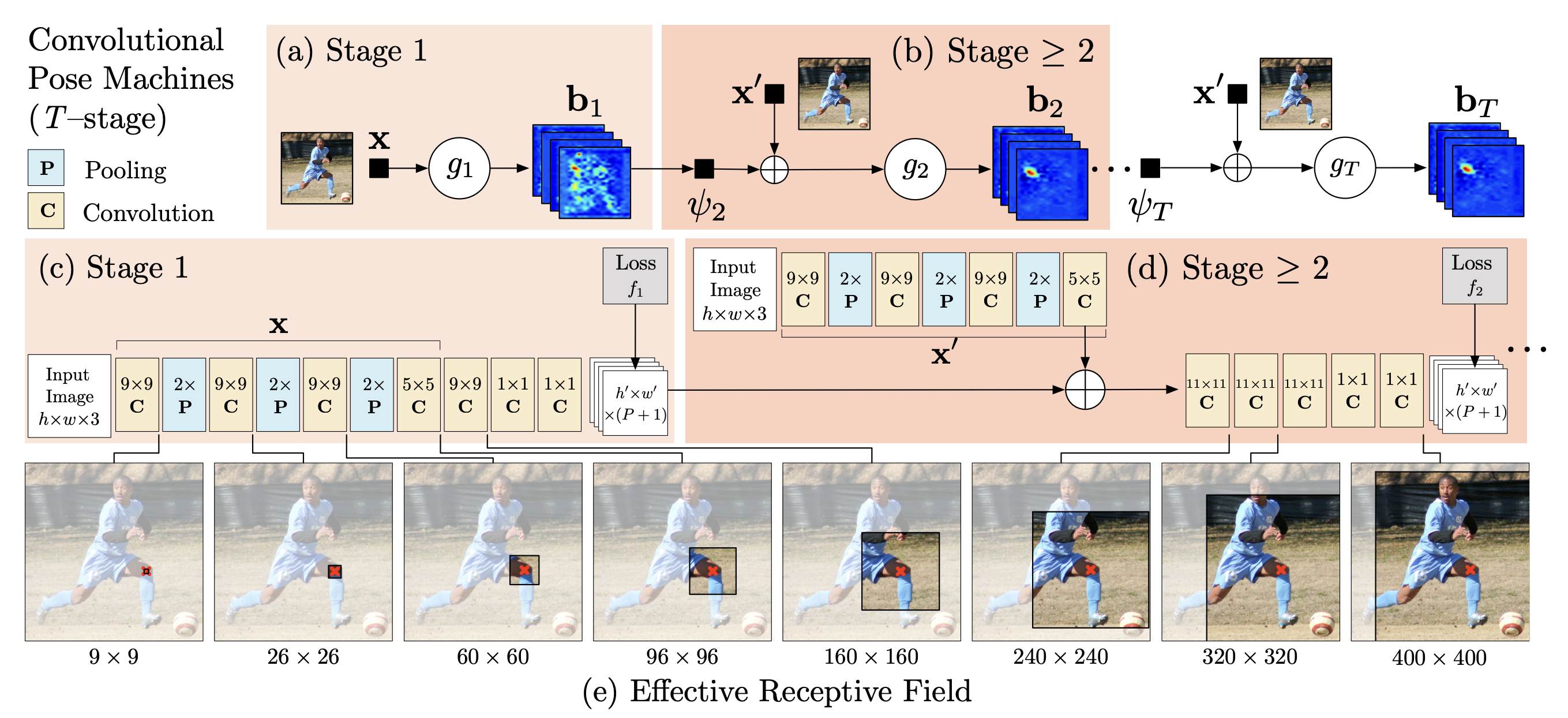
- 한계점
- 전역(Global Context) 과 지역(Local Context) 특징정보의 활용 부족
- CPM이 만들어지게 된 배경은 Receptive field를 키운다는 것, 쉽게 말해 크게 보자 라는 의미로 만들어지게 되었는데
Receptive field가 커지게 되면 Pooling을 확장해야하는데,
그렇게 되면 컨볼루션의 레이어의 수를 늘려야하고,
그렇게 되었을때 Local의 정보가 손실될 수 있는 가능성이 존재하게 됩니다.
즉, 여전히 세부적인 부분과 복잡한 포즈를 정확하게 인식하는 데 어려움이 존재하였고,
Global Context와 Local Context를 동시에 처리하는 데 제한이 있었습니다. - 이러한 한계점으로 인해 Hourglass Network라는 개념이 도입되었습니다.
- CPM이 만들어지게 된 배경은 Receptive field를 키운다는 것, 쉽게 말해 크게 보자 라는 의미로 만들어지게 되었는데
- 전역(Global Context) 과 지역(Local Context) 특징정보의 활용 부족
Single Person 2D Pose estimation - 3. Hourglass Network
HourGlass Network는 아키텍쳐가 모래시계와 같은 형상을 하고 있다고 해서 붙여지게 된 이름 인데,
Global Context, Local Context를 어떻게 잘 사용할 수 있을까? 라는 아이디어를 통해
2016년에 ECCV에서 나오게 되었습니다.
- 동작원리
- 아래 아키텍쳐를 보시면 Input이미지가 들어오게 되고
이미지를 다운스케일을 하여서 저해상도에서의 특징을 추출하고,
다시 업스케일을 하여서 고해상도에서의 세부 정보를 캡쳐합니다.
이 과정이 반복되면서 hourglass 형태의 구조가 만들어지게 됩니다.
- 아래 아키텍쳐를 보시면 Input이미지가 들어오게 되고
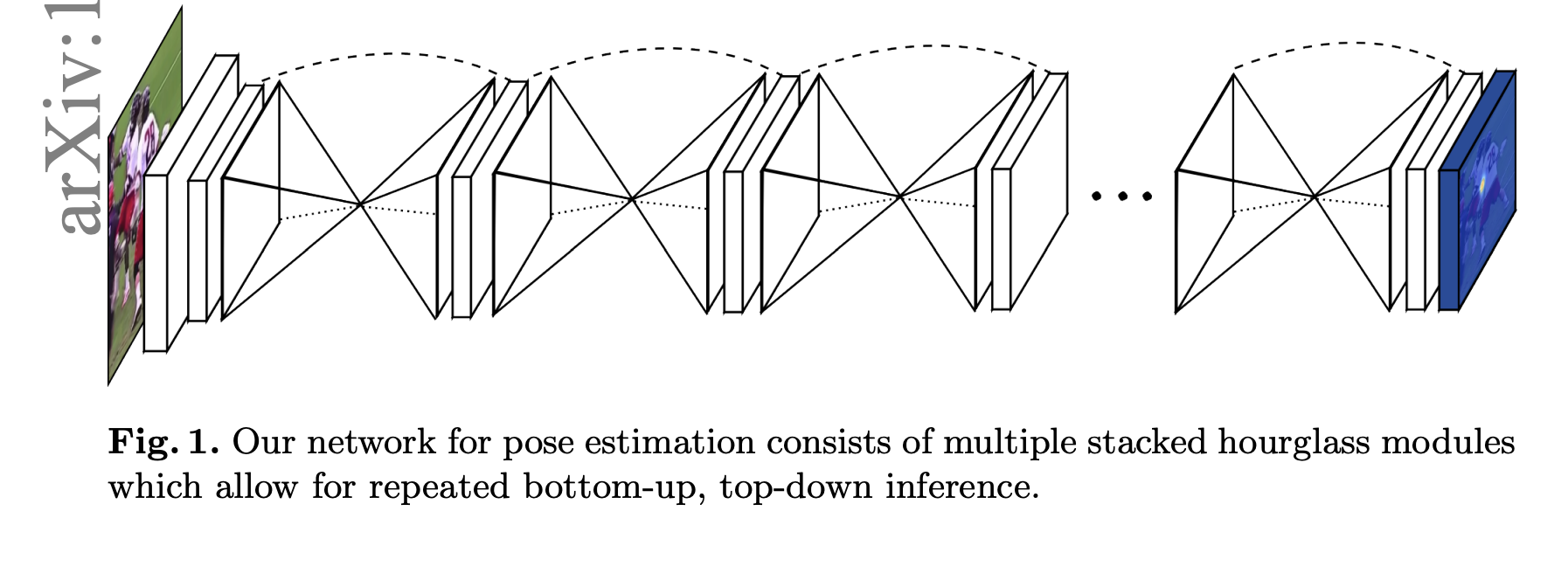
결과를 보시면 확실히 다중 스케일에서의 전역 + 지역적 특징을 활용한 Hourglass Network가 CPM보다 더 결과가 좋은 것을 확인하실 수 있습니다.
- 한계점
- 결국 위 와 같은 방법을은 이미지 내 여러 사람들이 존재할 때, 여러 사람의 관절 좌표를 탐지하는 것은 어려움이 존재합니다.
- CPM, Hourglass Network의 한계점을 보완 및 개선하여 카네기 멜론 대학에서 Multi Person을 탐지할 수 있는 OpenPose 논문이 등장하게 됩니다.
Multi Person 2D Pose estimation
- 정의 : 입력 이미지 내 사람이 두 명 이상 존재하는 경우를 의미합니다.
- Top Down Approach
- 사람을 우선적으로 탐지 후 탐지 결과 내에서 관절별 좌표를 예측하는 방법을 의미합니다.
대표적으로 Mask-RCNN 있고, 해당 방식의 문제점은 사람을 인식하지 못하면 측정이 어렵고, 사람 수가 많아지면 계산기 복잡해지는 문제점이 있습니다.
- 사람을 우선적으로 탐지 후 탐지 결과 내에서 관절별 좌표를 예측하는 방법을 의미합니다.
- Bottom Up Approach
- 이미지내에 탐지하고자 하는 관절에 대한 위치 예측 후 사람 별로 나누는 과정 진행하는 방법을 의미합니다.
선행 연구로 Deepcut(2016, CVPR)이 존재하였으나, 개별 이미지를 처리하는데 몇 초에서 이미지에 따라 수백 초 까지 걸리는 문제점이 존재하였습니다.
- 이미지내에 탐지하고자 하는 관절에 대한 위치 예측 후 사람 별로 나누는 과정 진행하는 방법을 의미합니다.
Multi Person 2D Pose estimation - 1. OpenPose Model
- OpenPose는 2017년 IEEE conference on Computer Vision and Patteren Recognition에서 발표가 되었고,
- 2019년 IEEE Transactions on Patteren Analysis and Machine Intelligence에 업데이트 개제가 되었습니다.
- OpenPose는 최초의 딥러닝 기반 실시간 2D 다중 인물 포즈 추정 기법입니다.

- 동작원리
- Bottom-up 방식
- 1. 영상 내의 모든 2D joint 추정하기
- Input 이미지가 들어오면 CNN을 통해서 모든 관절을 찾게 됩니다.
여기에서 CNN은 특징 맵 세트 F를 생성하며, 이는 아키텍쳐의 첫 번째 단계의 입력으로 사용됩니다. - 그럼 해당하는 관절이 어떤 사람의 것 이냐? 라는 것이 중요하게 되는데
이때 해당 논문에서는 Part Affinity Fields를 사용하여서 개별 사람의 포즈 검출 하였습니다.
- Input 이미지가 들어오면 CNN을 통해서 모든 관절을 찾게 됩니다.
- 2. Part Affinity Fields
- Concept
- 논문에 있는 아래 사진. (b)를 보시면 기존 CPM을 통해 이미지 내 사람의 관절 위치 추정이 가능해서
빨간점과 파란점 관절을 잘 찾을 수 있었지만 해당 관절이 어느 사람 것 인지에 대해서 여러가지 선을 그려가며 추정하는 문제를 볼 수 있습니다.
이것을 해결하기 위해서 중간에 노란색 점인 Mid Point를 생성하여서 해결하려고 했으나, 이미지가 복잡한 경우, 연결할 수 있는 여러 경우가 발생하는 문제점이 발생하였습니다.
이 문제점들을 해결하기 위해서 Part Affinity Fields 를 사용하였는데요.
- 논문에 있는 아래 사진. (b)를 보시면 기존 CPM을 통해 이미지 내 사람의 관절 위치 추정이 가능해서
- (b)-(c) 사진과 같이 Part Affinity Fields는 2차원 벡터 공간(방향 벡터)을 의미하며, 위치정보와 방향정보로 구성이 되어있습니다.
저자는 벡터의 방향과 위치를 추정할 수 있다면 동일 인물내에 혼돈을 주지않고, 제대로 연결할 수 있을 것이라고 생각을 하였고, 이렇게 두 관절 사이 연결 (limb)을 2차원 벡터로 인코딩을 할 수 있는 필터를 학습 시키게 됨으로써
그 사람에 해당하는 관절을 찾을 수 있게 되었습니다. - 여기에서 나온 결과물(Feature maps, PAFs of Stage)들이
Part Confidence Maps(heatmap)에 대한 입력변수로 활용됩니다.
- Concept
- 2. Part Confidence Maps(PCM의 Heatmap과 동일)
- Part Confidence Maps은 이미지 내에서 특정 부위(예: 머리, 팔, 다리 등)의 위치를 나타내는 2D 맵입니다.
각 픽셀의 값은 해당 위치에 특정 부위가 존재할 확률을 나타냅니다. - Part Affinity Fields과 Part Confidence Maps는 서로 병렬적으로 생성됩니다.
- PAFs와 동일한 네트워크 과정을 통해 PCMs를 추출합니다.
Convolution Pose Machines의 heatmap과 PCM은 동일하며, 같은 손실 함수를 사용합니다.주요 차이점
- Part Confidence Maps은 이미지 내에서 특정 부위(예: 머리, 팔, 다리 등)의 위치를 나타내는 2D 맵입니다.
- PCM, PAF 주요차이점
- 데이터 타입: Part Confidence Maps는 확률 맵이며, PAFs는 벡터 필드입니다.
- 정보의 종류: Part Confidence Maps는 인체 부위의 위치 정보를 제공하며, PAFs는 인체 부위 간의 연결성과 방향성 정보를 제공합니다.
- 활용 방안: Part Confidence Maps는 인체 부위의 위치를 식별하는 데 사용되며, PAFs는 이러한 부위를 연결하여 전체 인체 포즈를 구성하는 데 사용됩니다.
- OpenPose는 이 두 가지 정보를 통합하여 이미지 내의 인물들의 정확한 포즈를 실시간으로 추정합니다.
- 3. Bipartite Matching 단계
- PAFs를 사용하여 인체 부위 간의 최적의 연결을 찾습니다.
- 그래프 매칭을 이용하여서 PAFs와 Part Confidence Maps에서 얻은 정보를 기반으로 인체 부위 간의 연결을 식별합니다.
이 과정은 greedy relaxation 방법을 사용하여 고품질의 매칭을 생성합니다.
- 4. Parsing Results 단계
- 식별된 인체 부위와 연결을 바탕으로 이미지 내의 모든 인물의 전체 포즈를 구성합니다.
- 인체 부위와 PAFs의 정보를 통합하여서 각 인물의 포즈를 파싱하고 구성합니다.
이 정보는 최종적으로 인물의 포즈를 식별하고 추적하는 데 사용됩니다.
- 1. 영상 내의 모든 2D joint 추정하기
- Bottom-up 방식
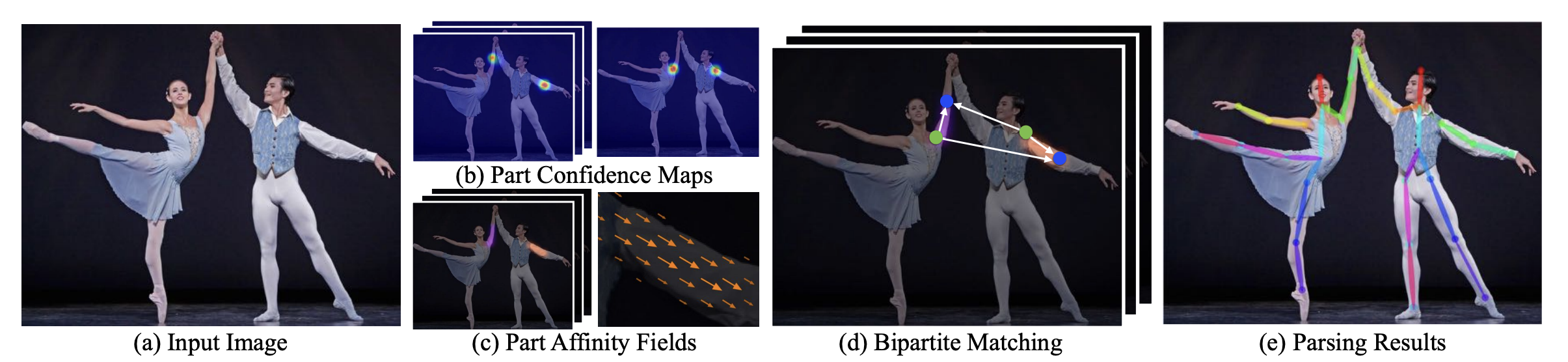

- 아키텍쳐 분석
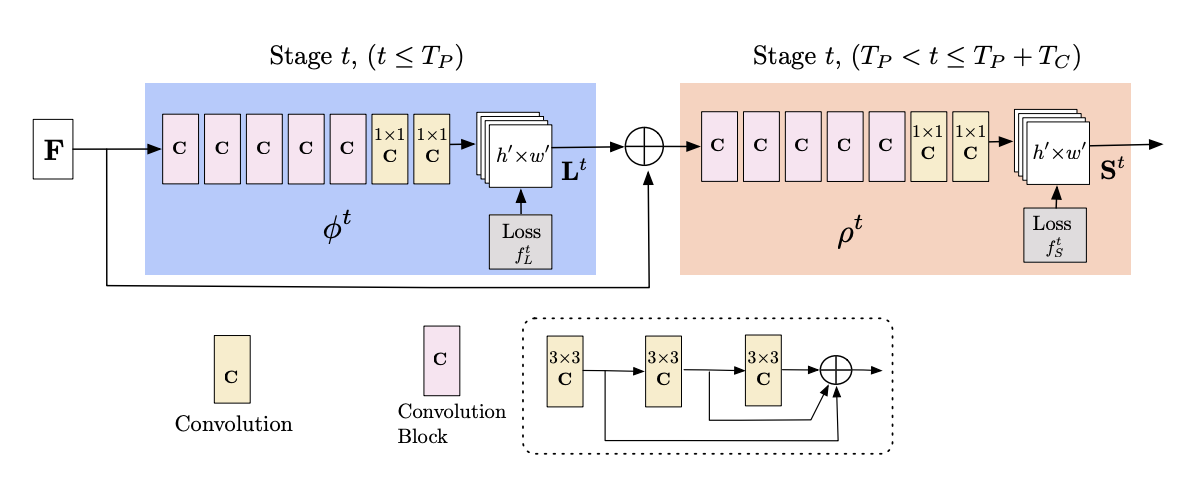
- OpenPose의 아키텍처는 이미지를 분석하는 CNN(Convolutional Neural Network)으로 시작합니다.
VGG-19를 통해 추출한 CNN은 특징 맵 세트 F를 생성하며, 이는 첫 번째 단계의 입력으로 사용됩니다. - 5개의 Convolution Block과 1x1 필터를 사용하는 convolution layer를 거쳐서 PAFs L1을 생성하고
여기서 φ1은 첫 번째 단계에서 추론을 위한 CNN을 나타냅니다. - PAFs는 여러 단계에 걸쳐 계산됩니다.
각 단계에서 네트워크는 이전 단계의 PAFs와 원본 이미지의 특징을 결합하여 더 정확한 PAFs를 생성합니다. - 여기에서 나온 결과물(Feature maps, PAFs of Stage)들이
Part Confidence Maps(heatmap)에 대한 입력변수로 활용됩니다. - 해당 아키텍쳐로 PAFs와 Part Confidence Maps는 병렬적으로 생성되며, 이들은 함께 작동하여 이미지 내의 인체 포즈를 추정합니다.
- OpenPose의 아키텍처는 이미지를 분석하는 CNN(Convolutional Neural Network)으로 시작합니다.
위 순서에 따라 PAFs들이 잘 추정이 되었는지 Stage별로 확인을 해보겠습니다.
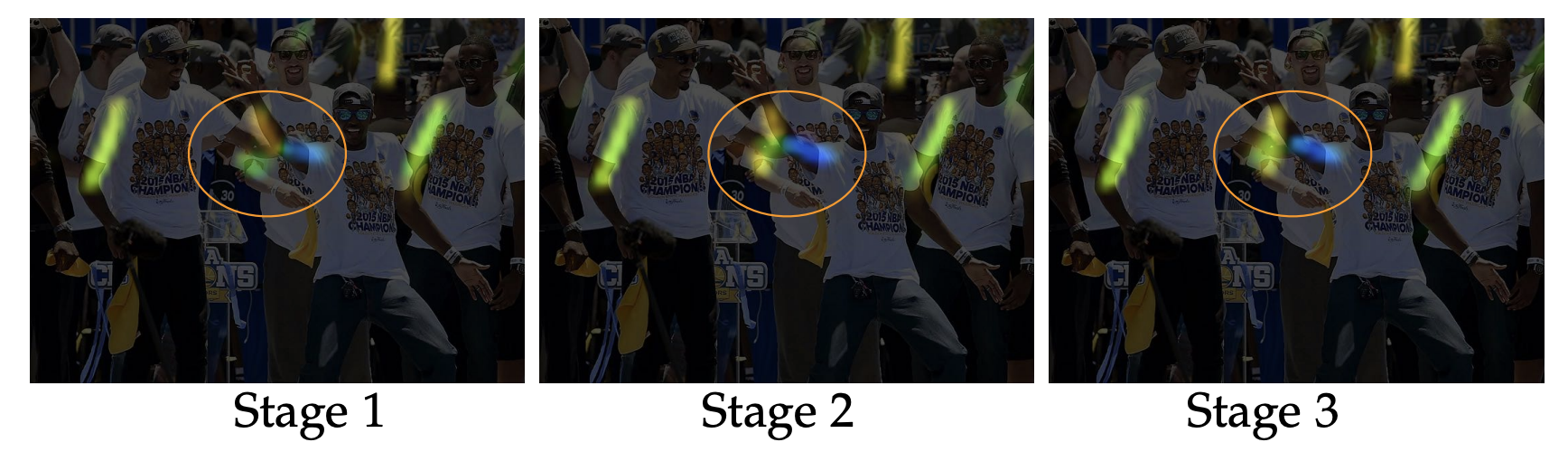
- Stage1
- 주황색으로 표시 된 사람의 팔뚝이 잘 인식이 안되고 있는 것을 확인할 수 있습니다.
- Stage2
- 주황색으로 표시 된 사람의 팔뚝이 이전보다 잘 인식 된 것을 확인하실 수 있습니다.
- Stage3
- 동그라미 친 부분의 노란색으로 표시 된 사람의 팔뚝이 잘 인식된 것을 확인하실 수 있습니다.
결론
이러한 단계를 거쳐 OpenPose는 실시간으로 이미지 내의 여러 인물의 포즈를 정확하게 추정하고 분석할 수 있고
각 단계는 서로 연결되어 있으며, 전체 프로세스는 인체 포즈 추정의 정확도와 효율성을 최적화 하여 포즈를 추측할 수 있습니다.
여기까지 Human Pose Estimation이 무엇인지, 2D HPE(Human Pose Estimation)에 대해서 알아보았습니다.
다음 포스팅에서는 3D HPE에 대해서 알아보겠습니다.
참고링크 및 논문
https://www.sciopen.com/article/pdf/10.26599/TST.2018.9010100.pdf?ifPreview=0
https://arxiv.org/pdf/2012.13392.pdf
https://viso.ai/deep-learning/pose-estimation-ultimate-overview/
https://arxiv.org/pdf/1312.4659.pdf
https://arxiv.org/abs/2006.01423v1
https://ctkim.tistory.com/entry/Convolutional-Pose-Machines-CPM
https://paperswithcode.com/paper/convolutional-pose-machines
https://arxiv.org/abs/1603.06937



