
민프
[AI] MobileNetV2에 대해서 알아보자 (MobileNetV2: Inverted Residuals and Linear Bottlenecks 리뷰) 본문
[AI] MobileNetV2에 대해서 알아보자 (MobileNetV2: Inverted Residuals and Linear Bottlenecks 리뷰)
민프야 2023. 10. 16. 09:49이번 포스팅에서는 MobileNetsV2에 대해서 알아보겠습니다.
MobileNetsV1에 대해서 선행 학습이 되어있어야해서 잘 모르시는 분께서는
아래 링크를 통해서 보고 오시기 바랍니다.
[AI] MobileNets 에 대해서 알아보자 (MobileNets - Efficient Convolutional Neural Networks for Mobile Vision Applications
이번 포스팅에서는 MobileNets에 대해서 알아보겠습니다. 소개 및 등장배경 2017년 Google에서 발표한 논문 입니다. 모델 경량화 딥러닝 모델에 대해서 요즘에는 스마트폰, 자동차, 드론 등등 여러 분
minf.tistory.com
소개
MobileNetV2는 Google에서 2018년에 발표한 논문입니다.

MobileNetV1의 핵심 Key는depthwise separable convolutions이었습니다.
MobileNetV2의 핵심 Key는 논문 제목에서 알 수 있 듯
depthwise separable convolutions + Inverted Residuals, Linear Bottlenecks 입니다.
또한 아래 논문 소개 글을 보면
inverted residual with linear bottleneck. This module takes as an input a low-dimensional compressed representation which is first expanded to high dimension and filtered with a lightweight depthwise convolution.
MobileNetV2 주요 기여 중 하나는 새로운 레이어 모듈인 "inverted residual with linear bottleneck" 이고,
이 모듈은 저차원의 압축된 표현을 입력으로 받아 고차원으로 확장하고 경량화된 depthwise convolution으로 필터링 한다고 합니다.
그러면 먼저 inverted residual with linear bottleneck 대해서 알아보겠습니다.
inverted는 '거꾸로' 의 의미를 가지고 있습니다.
그럼 먼저 Residual Blocks는 어떤 것인지 알아보겠습니다.
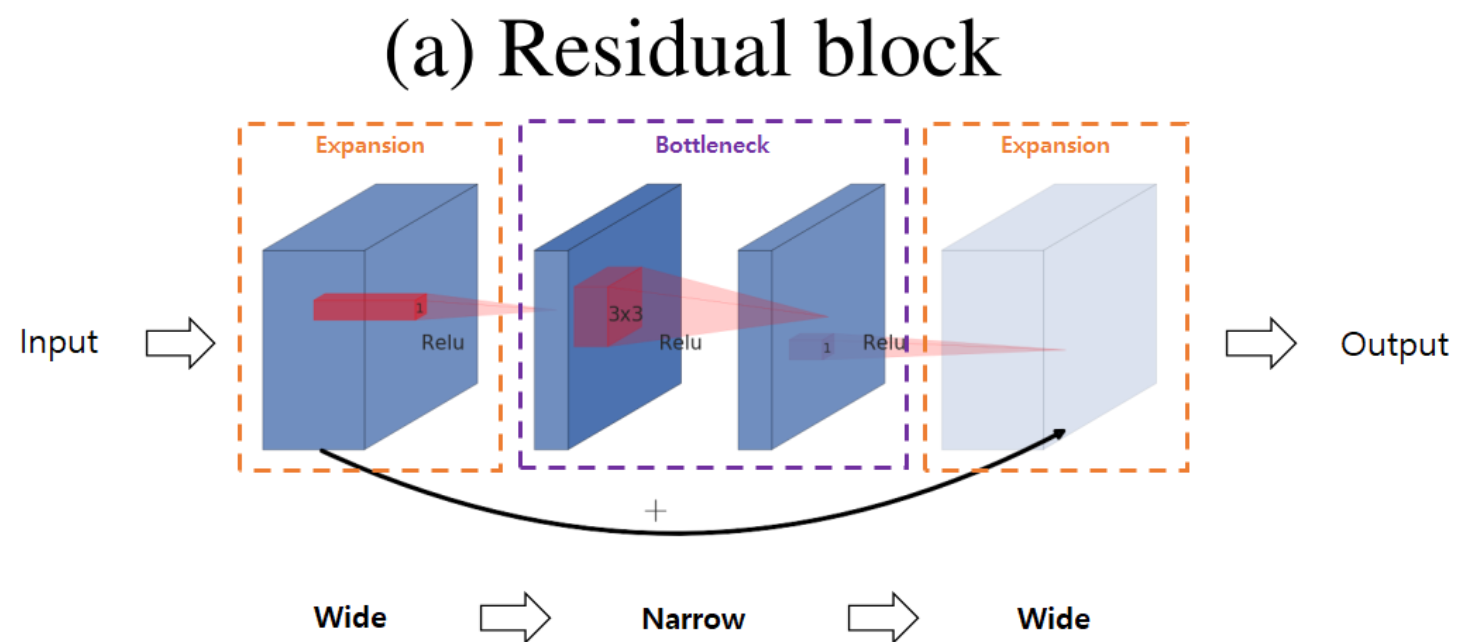
Residual Blocks
Residual Blocks은 ResNet에서 처음 소개되었습니다.
아래 그림에서 나오는
Bottleneck Block에 대해서 간단하게 설명해보자면
Residual Blocks in Bottleneck block은 ResNet에서 주로 사용되는 구조로,
입력 특징 맵의 차원을 줄이고,중간 계산을 수행한 후, 출력에서 다시 차원을 늘리는 구조입니다.
즉, 1x1 컨볼루션으로 차원을 줄이고, 3x3 컨볼루션으로 특징을 처리한 후, 다시 1x1 컨볼루션으로 차원을 늘립니다.
아래 구조를 봐보겠습니다.
1. 큰 채널이 들어와서(Wide) -> 적은 수의 채널을 갖는 bottleneck block을 생성합니다.
2. bottleneck block에서 3x3 Conv Layer를 통과한 뒤 (narrow) ->
3. Residual Connection을 연결하기 위해 다시 1x1 Conv Layer를 활용해 채널 수가 많은 extension block을 생성합니다. (Wide)
Inverted Residual Blocks
Inverted Residual Blocks은 반대로
Linear Bottleneck in Inverted Residual Blocks 이 사용되는데요 (그림에서는 BottleNect이라고 나와있음)
여기에서 Linear Bottleneck에 대해서 말씀드려보겠습니다.
Linear Bottleneck은 MobileNetV2의 Inverted Residual Blocks에서 사용됩니다.
이 구조는 효율적인 계산과 높은 정확도를 동시에 달성하기 위해 설계되었습니다
여기서 "Linear"은 마지막 레이어에 비선형 활성화 함수를 사용하지 않는다는 것을 의미합니다.
즉, 먼저 입력 특징 맵의 차원을 확장(1x1 컨볼루션),
그런 다음 3x3 depthwise 컨볼루션으로 특징을 처리하고,
마지막으로 1x1 컨볼루션으로 차원을 줄이면서 비선형 활성화 함수를 사용하지 않습니다.
아래 구조를 봐보겠습니다.
낮은 차원의 Input을 받습니다. ->
1x1 Conv (Narrow) ->
3x3로 Conv 확장하고 채널이 커진 상태에서
Depthwise Separable Convolution을 수행하여 특징 추출(Feature extraction)이 일어나게 되고 (Wide) ->
1x1 Conv으로 채널을 다시 줄이게 됩니다. (Narrow)
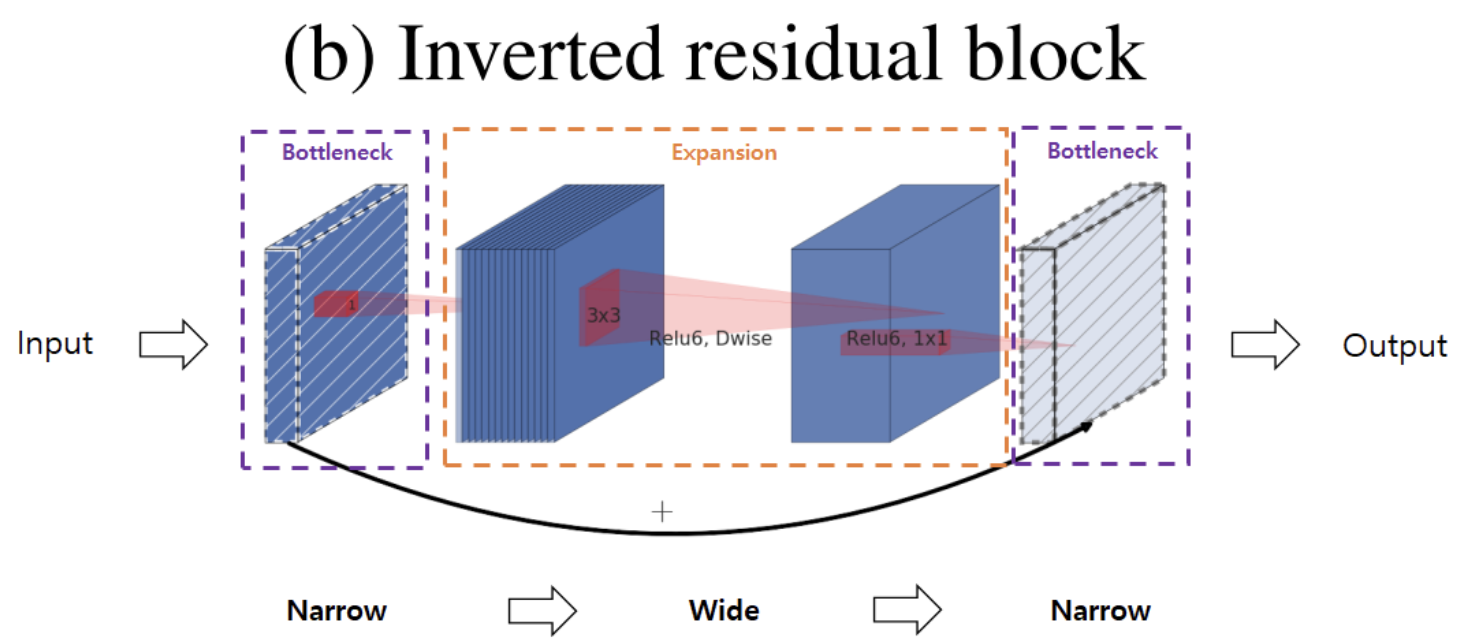
Inverted Residual Block은 입력과 출력의 채널수가 낮기 때문에 Residual block보다 메모리 효율이 좋은 장점이 있습니다.
아키텍쳐 분석
MobileNetV1, MobileNetV2 차이점
- 아래 순서도를 보시는 것 과 같이 MobileNetV2에서는 Stride 값에 따라서 두 가지 블록으로 나뉘게 됩니다.
- Stride 1
- 주로 정보를 보존하고, 특징을 추출하는 데 중점을 둡니다.
- Inverted Residuals와 Linear Bottleneck이 사용됩니다.
- feature map의 크기를 변경하지 않습니다
- residual connection 을 추가하여 그래디언트의 전파를 개선하고, 학습을 안정화시킵니다.
- Stride 2
- feature map의 크기를 줄이는 데 사용됩니다 (다운샘플링).
- residual connection 을 추가하지 않습니다.(왜 추가하지 않는건 논문에 나와있지 않음..)
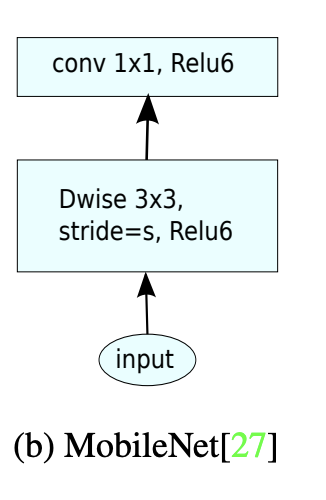

Bottlenect Residual Block 구조
Inverted Residual Blocks - Bottlenect Residual Block 구조를 보겠습니다.
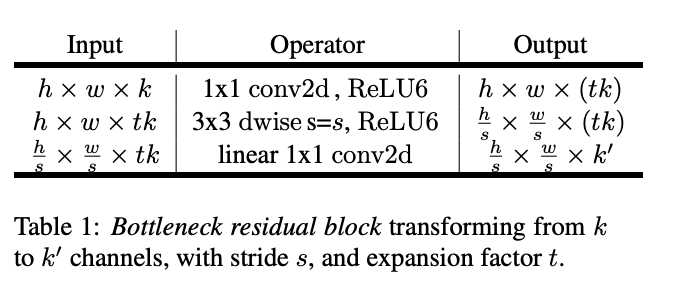
- Input: h x w x k
원본 이미지 또는 이전 레이어의 출력이 이 단계의 입력으로 들어옵니다. 이미지의 높이는 h, 너비는 w, 채널 수는 k입니다.
Operator: 1x1 conv2d, ReLU6
1x1 conv2d: 입력 특징 맵의 채널 수를 t배로 확장합니다. 이를 통해 모델이 더 복잡한 특징을 학습할 수 있게 됩니다.
ReLU6: 비선형 활성화 함수로, 특징 맵의 각 요소의 값을 0과 6 사이로 제한합니다.
결과적으로
이미지의 높이와 너비는 동일하게 유지되지만, 채널 수가 tk로 확장되어 더 다양한 특징을 표현할 수 있게 됩니다.
Output: h × w × (tk)
h × w: 특징 맵의 높이와 너비는 변하지 않습니다.
tk: 채널 수가 t배로 확장되어, 입력 채널 수 k에 t를 곱한 값이 됩니다.
결과적으로
이미지의 높이와 너비는 변하지 않았지만, 채널의 다양성이 증가하여 이미지의 복잡한 특징을 더 잘 표현할 수 있게 되었습니다. - Input: h x w x tk
이전 과정의 Output 결과값이 Input으로 들어오게 됩니다.
Operator: 3x3 dwise s=s, ReLU6
3x3 dwise: depthwise 컨볼루션을 통해 각 채널에서 공간적 특징을 독립적으로 추출합니다.
s=s: 스트라이드 값이 s로 설정되어, 특징 맵의 높이와 너비가 s의 배수로 줄어듭니다.
ReLU6: 비선형 활성화 함수를 추가합니다.
결과적으로 공간적 차원이 축소되고, 각 채널 내에서 더 정교한 특징이 추출됩니다.
Output: h/s × w/s × (tk)
특징 맵의 공간적 차원이 줄어들고, 각 채널이 이미지의 더 정교한 특징을 포착하고 있습니다. - Input : h/s × w/s × (tk)
이전 과정의 Output이 Input으로 들어오게 됩니다.
Operator: linear 1x1 conv2d
채널 수를 k'로 줄이는 선형 1x1 컨볼루션을 적용합니다. 이 과정은 특징 맵을 압축하고, 필요한 특징만을 유지합니다.
결과적으로 채널 수가 감소하고, 특징 맵이 압축됩니다. 이는 계산 효율성을 높이고, 중요한 특징만을 유지합니다.
Output: h/s × w/s × k'
최종적으로, 특징 맵의 공간적 차원이 축소되고, 채널 수도 압축되어 있습니다. 이 특징 맵은 다음 레이어로 전달되거나, 네트워크의 출력으로 사용됩니다.
MobileNetV2 성능
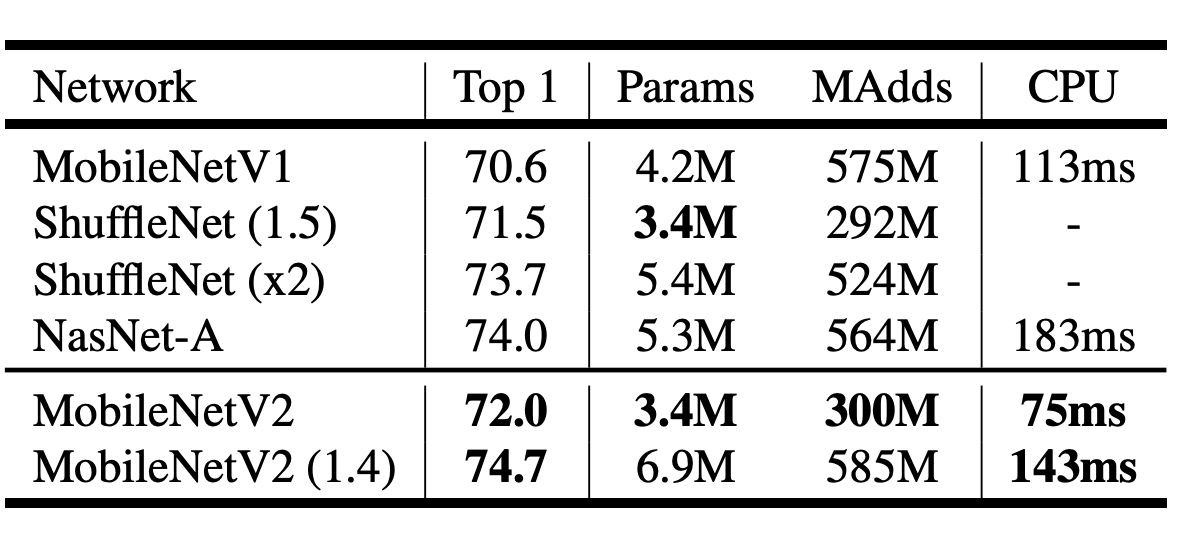
결론적으로 MobileNetV2의 성능을 비교하면 기존 MobileNetV1보다 향상된 정확도와 더 적은 파라미터 값을 가지게 되며
이는 더 적은 컴퓨팅 성능을 요구할 수 있습니다.
참고 링크
https://arxiv.org/abs/1801.04381



