
민프
[AI | ML][ML][GBDT] LightGBM (LGBM) 본문
1. LightGBM이란?

LightGBM은 마이크로소프트에서 개발한 Gradient Boosting Decision Tree(GBDT) 기반의 머신러닝 프레임워크입니다.
기존 GBDT의 단점인 느린 학습 속도와 높은 메모리 사용량을 극복하기 위해 만들어졌고, 대표적인 GBDT 구현체 중 하나인 XGBoost보다도 훨씬 빠르고 효율적입니다.
아래는 LightGBM의 공식 깃헙입니다.
https://github.com/microsoft/LightGBM
GitHub - microsoft/LightGBM: A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework ba
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning ...
github.com
2. LightGBM만의 기술
논문에서 서문에 나와있듯
기존 GBDT의 문제점은 아래와 같았습니다.
- 데이터가 커질수록 학습 속도가 매우 느려짐
- 특성이 많을수록 split 계산량이 폭발적으로 증가
- 메모리 사용량이 큼

이 문제를 해결하기 위해 LightGBM은 2가지 핵심 기법을 도입합니다.
2-1. GOSS (Gradient-based One-Side Sampling)

위 와 같이 논문에서 GOSS를 설명하고 있습니다.
GOSS는 Gradient-based One-Side Sampling의 약자로,
훈련 데이터를 샘플링할 때 gradient 값이 큰 데이터는 모두 유지하고,
gradient 값이 작은 데이터는 일부만 선택해서 훈련에 사용하는 방식입니다.
쉽게 말해
“모델이 틀리게 예측한 샘플(gradient가 큰)은 중요하니까 모두 사용하고,
모델이 잘 맞춘 샘플(gradient가 작은)은 일부만 사용해서 계산량을 줄이자“는 접근입니다.
2-1-1. 왜 GOSS(Gradient-based One-Side Sampling)가 필요한가?
기존의 Stochastic Gradient Boosting (SGB)는 전체 데이터 중 무작위로 일부를 샘플링하여 속도를 높입니다.
하지만 이 방법은 중요한 샘플(예: 오차가 큰 샘플)을 놓칠 수도 있어 성능 저하가 발생할 수 있습니다.
GOSS는 SGB의 이런 약점을 보완하기 위해 등장했습니다.
오차가 큰 샘플은 모두 포함시키고,
오차가 적은 샘플만 무작위로 일부 뽑아서 효율성과 정확도를 동시에 잡는 전략입니다.
여기에서 핵심 개념은 바로 One-Side Sampling 입니다.
One-Side Sampling이란 위에서 설명했듯 작은 Grdient만 drop하는 것을 의미합니다.
- 일반 샘플링은 양쪽에서 고르게 선택 (잘 맞춘 샘플 + 못 맞춘 샘플)
- One-Side Sampling은 “한쪽만” 강조해서 선택
- 즉, gradient가 큰 한쪽만 전체 선택, 다른 쪽은 일부만 선택
따라서 이게 “Gradient 기반 One-Side Sampling”이라는 이름의 이유입니다.
2-1-2. GOSS(Gradient-based One-Side Sampling) 동작 알고리즘

설명을 해드리자면 아래와 같습니다.
Algorithm 2: Gradient-based One-Side Sampling
Input: I: training data, d: iterations
• I는 전체 학습 데이터
• d는 반복할 boosting 단계 수 (트리 수)
Input: a: sampling ratio of large gradient data
Input: b: sampling ratio of small gradient data
• a: Gradient가 큰 데이터 중 얼마나 사용할 것인지 비율
• b: Gradient가 작은 데이터 중 얼마나 사용할 것인지 비율
예시) a = 0.2, b = 0.1 → 상위 20% gradient 큰 샘플은 전부 사용, 나머지 중 10%만 샘플링
Input: loss: loss function, L: weak learner
• loss: 손실함수 (예: MSE, Log loss)
• L: 약한 학습기 (즉, 결정 트리)
models ← {}, fact ← 1−a/b
• models: 학습한 트리 모델들을 저장할 리스트
• fact: 작은 gradient 데이터를 샘플링한 만큼 보정할 가중치 값
topN ← a × len(I) , randN ← b × len(I)
• topN: gradient가 큰 샘플 중 사용할 개수
• randN: gradient가 작은 샘플 중 랜덤하게 선택할 개수
for i = 1 to d do
• 트리를 총 d번 학습합니다 (Boosting step 반복)
preds ← models.predict(I)
• 현재까지 학습된 모델로 전체 데이터에 대한 예측을 수행
g ← loss(I, preds), w ← {1,1,...}
• 각 샘플마다 gradient (g)를 계산합니다.
• w는 각 샘플에 대한 가중치 배열 (처음엔 모두 1)
sorted ← GetSortedIndices(abs(g))
• gradient의 절댓값 기준으로 정렬된 인덱스 리스트를 얻음
topSet ← sorted[1:topN]
• gradient가 가장 큰 topN개의 인덱스 추출 → 중요한 샘플
randSet ← RandomPick(sorted[topN:len(I)],randN)
• 나머지 작은 gradient 중 randN개 랜덤 추출 → 덜 중요한 샘플
usedSet ← topSet + randSet
• 사용될 최종 데이터셋은 중요 샘플 + 일부 덜 중요한 샘플
w[randSet] × = fact . Assign weight f act to the small gradient data.
• gradient가 작은 샘플들은 적게 쓰였으니 가중치를 보정
• fact = (1 - a) / b → 전체 분포를 다시 맞추기 위함
newModel ← L(I[usedSet], − g[usedSet],w[usedSet])
• 선택된 샘플로 약한 모델 L을 학습
• 학습 대상은 샘플과 그에 대한 gradient (또는 residual)
models.append(newModel)
• 학습된 모델을 모델 리스트에 저장2-2. EFB (Exclusive Feature Bundling)란?

결론적으로 LightGBM이 속도와 메모리 효율을 극적으로 향상시킬 수 있었던 비결 중 하나가 바로 이 EFB이고,
논문에서 설명하는 글과 같이 EFB는 서로 동시에 0이 아닌 값을 갖지 않는 희소한 특성들(=exclusive features)을 하나의 피처로 묶어주는 기술입니다.
여기에서 one-hot features를 포함했다고 하는데 one-hot이라는게 무엇일까요?
"one-hot encoding (원-핫 인코딩)" 은 범주형 데이터를 숫자로 바꿔서 머신러닝 모델이 이해할 수 있도록 만드는 가장 기본적인 방법입니다.
예를 들어서)
요일 데이터를 one-hot 인코딩하면
원래 이렇게 생겼다고 가정해보겠습니다.
| 요일 |
| 월 |
| 화 |
| 수 |
-> 머신러닝은 문자열을 이해 못 하니까, 숫자 벡터로 바꿔줘야 합니다.
One-Hot 인코딩 결과 입니다.
| 요일_월요일 | 요일_화요일 | 요일_수요일 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
왜 이런 One-Hot 인코딩을 쓰는걸까요?
- 문자열을 숫자로 변환하면서 값의 크기가 의미 없도록 하기 위해서 입니다.
- 예: 월=1, 화=2, 수=3 이런 식이면 모델이 “수요일이 더 큰 값이니까 더 중요해!“라고 오해할 수 있게 됩니다.
- 반면 One-hot은 순서나 크기 정보 없이 단순히 해당 여부만 나타냅니다.
자 그럼 다시 본론으로 돌아와서
2-2-1. EFB (Exclusive Feature Bundling)가 왜 필요한가?
- 대규모 데이터셋에는 one-hot encoding된 특성이 매우 많음 → 차원이 수천, 수만까지 늘어남
- 하지만 대부분의 경우, 동시에 활성화되는 특성은 없음
- 예: 요일_월, 요일_화, 요일_수 (위 표 참고)는 서로 배타적(exclusive)임 → 한 번에 하나만 1
- 이럴 경우, 낭비되는 feature 공간을 줄이고, 메모리 사용량을 줄이며 속도를 향상시킬 수 있음
여기에서 핵심 아이디어는 아래와 같습니다.
“배타적(exclusive)“인 feature들은 하나로 묶을 수 있다
자 그럼 또 여기서 베타적인 featrue란 무엇일까요??
배타적(exclusive)인 feature란?
동시에 1이 될 일이 없는 one-hot 인코딩된 피처들을 말합니다.
즉, 어떤 샘플에서도 이 feature들과 이 feature들은 절대 동시에 non-zero가 되지 않는다는 특징이 있어요.
위 표에서 볼 수 있듯이, 월/화/수는 한 샘플에서 동시에 두 개가 1이 될 수 없습니다.
->이것들을 서로 배타적이다고 합니다.
| 요일_월요일 | 요일_화요일 | 요일_수요일 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
그럼 베타적인 feature들을 묶는게 무엇인지 요일 예시로 들어보겠습니다.
| 예시 | 요일_월요일 | 요일_화요일 | 요일_수요일 | → 하나의 묶음 |
| 샘플1 | 1 | 0 | 0 | → 0 |
| 샘플2 | 0 | 1 | 0 | → 1 |
| 샘플3 | 0 | 0 | 1 | → 2 |
이런 걸 왜 하나로 묶을 수 있을까요?
이런 배타적인 피처들은 동시에 1이 될 수 없으니까,
한 개의 컬럼 안에 숫자만 잘 구분(0,1,2)해서 담을 수 있습니다.
묶으면 뭐가 좋을까요?
메모리 절약
- 예전엔 3개의 열이었는데 이제는 1개니까.
위 표가 아래와 같이 나타나지게 됩니다.
| Bundle |
| 월요일(0) |
| 화요일(1) |
| 수요일(2) |
속도 향상
- 연산해야 할 feature가 줄어들어서 LightGBM이 훨씬 빨리 학습합니다.
2-2-2. EFB (Exclusive Feature Bundling) 동작 알고리즘
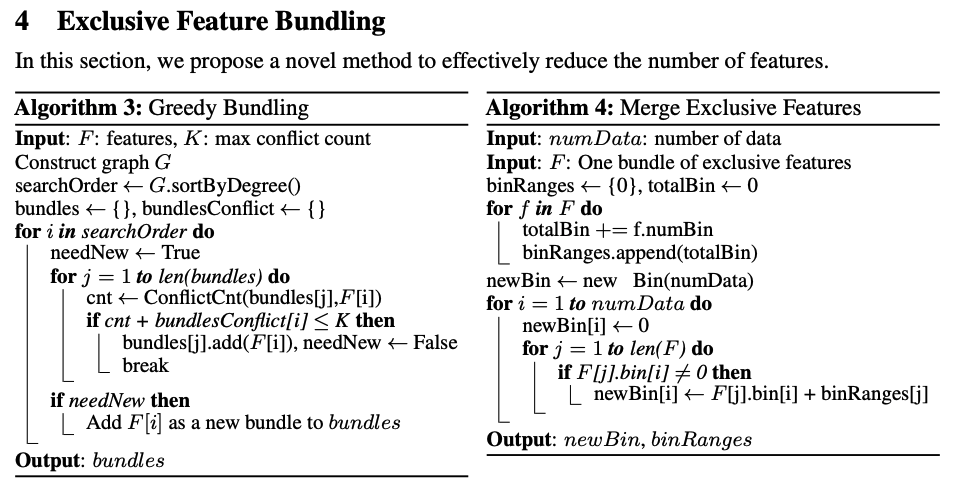
- Greedy Bundling (탐욕 기반 피처 묶기)
Input: F: features, K: max conflict count
👉 F는 전체 피처 리스트고, K는 두 feature가 함께 1이 되는 최대 허용 횟수입니다 (즉, 겹쳐도 되는 한계치).
Construct graph G
👉 각 feature를 노드, 두 feature가 서로 동시에 1인 경우 간선으로 하는 그래프 G를 만듭니다.
searchOrder ← G.sortByDegree()
👉 연결(간선)이 적은 노드부터 우선 탐색하도록 정렬합니다. (= conflict가 적은 feature 먼저 묶기)
bundles ← {}, bundlesConflict ← {}
👉 bundles: 실제로 묶은 피처 집합들
👉 bundlesConflict: 각 묶음이 얼마나 conflict가 발생했는지 저
for i in searchOrder do
👉 정렬된 순서대로 feature를 하나씩 검사합니다.
needNew ← True
👉 이 feature를 기존에 있는 bundle에 넣을 수 없다면, 새로운 묶음을 만들어야 하므로 True로 시작합니다.
for j = 1 to len(bundles) do
👉 기존의 각 bundle을 순회하면서,
cnt ← ConflictCnt(bundles[j],F[i])
👉 현재 feature(F[i])와 j번째 묶음이 겹치는 횟수(cnt)를 구합니다.
if cnt + bundlesConflict[i] ≤ K then
👉 해당 묶음에 이미 conflict가 좀 있지만, 현재 feature까지 더해도 K 이하라면, 괜찮으니 추가합니다.
bundles[j].add(F[i]), needNew ← False
break
👉 현재 feature를 이 bundle에 추가하고, 새 묶음 만들 필요 없다고 표시하고 반복 종료.
if needNew then
Add F[i] as a new bundle to bundles
👉 위의 for문에서 넣을 수 없었다면, 새로운 bundle 생성.
Output: bundles
👉 conflict를 최소화하며 만들어진 feature 묶음들 반환.
- Merge Exclusive Features (묶은 피처 실제로 합치기)
Algorithm 4: Merge Exclusive Features
Input: numData: number of data
Input: F: One bundle of exclusive features
👉 F는 Algorithm 3에서 나온 하나의 feature 묶음, numData는 전체 샘플 개수
binRanges ← {0}, totalBin ← 0
👉 각 feature가 가진 bin 수를 저장할 리스트와, 전체 누적 bin 개수 초기화
for f in F do
totalBin += f.numBin
binRanges.append(totalBin)
👉 각 feature의 bin 개수를 누적해 가며 저장
(예: 첫 feature가 bin 3개 → 다음 feature는 3부터 시작해야 겹치지 않음)
newBin ← new Bin(numData)
👉 최종적으로 합쳐질 새로운 feature vector
for i = 1 to numData do
newBin[i] ← 0
👉 모든 row에 대해 초기값 0으로 설정
for j = 1 to len(F) do
if F[j].bin[i] 6= 0 then
newBin[i] ← F[j].bin[i] + binRanges[j]
👉 row i에서 j번째 feature의 값이 0이 아니면:
그 값에 오프셋(binRanges[j])을 더해서 겹치지 않게 newBin에 저장
Output: newBin, binRanges
👉 합쳐진 feature와 각 feature의 오프셋 정보를 반환
2-3. Leaf-wise, Level-wise

논문에서 leaf-wise 전략을 사용한다고 했는데
이게 뭘까?
간단하게 Decision Tree에 대해서 설명하자면
- 결정 트리(Decision Tree)는 데이터를 분할하여 예측을 수행하는 구조입니다.
- 트리는 루트 → 내부 노드 → 리프(leaf)로 구성되며,
- 리프 노드는 최종 예측값을 의미합니다.
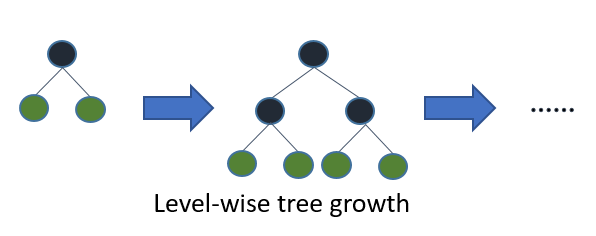
2-3-2. Level-wise (XGBoost 방식)
- 트리의 모든 레벨을 균형 있게 확장합니다.
Level(균등, 수평) wise(분할) 방식은 tree를 수평적으로 키웁니다.
따라서 tree를 균형적으로 만들기 위한 추가 연산이 필요하기 때문에 상재적으로 속도가 느립니다.
병렬 처리에 유리합니다. - 예시 (모든 리프 노드가 균일한 깊이)
- 1단계 → 트리 깊이 1
- 2단계 → 트리 깊이 2
- 3단계 → 트리 깊이 3
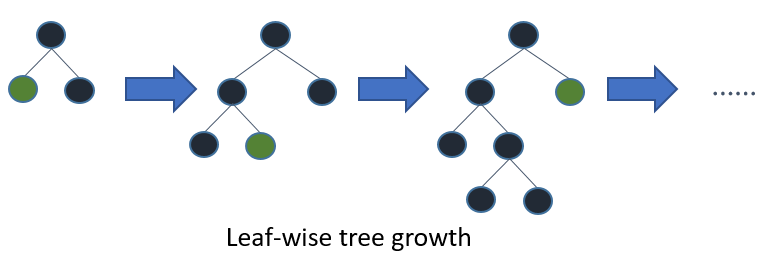
2-3-3. Leaf-wise (LightGBM 방식)
- 트리의 가장 손실 감소가 큰 leaf 하나만 계속 분할합니다.
delta loss가 가장 큰 값을 선택하여 다시 subtree로 분할하는 방법입니다.
즉 성능을 가장 낮추는(loss가 가장 큰) node를 선택해 loss를 줄여 나가는 방식 입니다.
따라서 상대적으로 속도가 빠르고 예측을 최소화 시킬 수 있습니다.
단점으로는 과적합 위험이 존재합니다. - 예시 (전체 트리는 비대칭 구조)
- 1단계 → 트리 깊이 1
- 2단계 → 손실 큰 리프만 깊이 2로 확장
- 3단계 → 또 손실 큰 리프만 확장
3. LightGBM 의 전체 동작과정
자 그럼 전체 동작 과정은 어떻게 될까?
아래와 같이 나타낼 수 있습니다.
[Raw Sparse Features]
↓ EFB
[Bundled Features]
↓
[Initial Model (avg)]
↓
[Residual Calculation]
↓ GOSS
[Sampled + Weighted Data]
↓
[Leaf-wise Tree Generation]
↓
[Model Update]
↺ 반복
1단계: 데이터 전처리 (EFB 적용)
- 입력: 매우 많은 수의 sparse feature (특히 one-hot encoding된 feature들)
- EFB(Exclusive Feature Bundling) 적용
- 서로 배타적인 sparse feature들을 한 번에 하나의 feature로 묶음
- 예: 1000개의 one-hot feature를 300개로 줄일 수 있음
- 결과: feature 수가 줄고, 메모리 절약 + 계산량 감소
2단계: 초기 예측 모델 생성
- 보통 첫 번째 트리는 평균값이나 기본 예측값을 사용하는 약한 모델로 시작
3단계: 잔차(오차) 계산
- 현재 모델의 예측값과 실제값의 차이인 잔차(residuals)를 계산
- 이 값들이 다음 트리가 학습할 목표값이 됨
4단계: 데이터 샘플링 (GOSS 적용)
- GOSS(Gradient-based One-Side Sampling) 적용:
- 모든 샘플 중 gradient가 큰 샘플은 모두 유지
- gradient가 작은 샘플은 일부만 랜덤 샘플링
- 선택된 샘플에 가중치 보정(factor)를 곱해서 데이터 분포 보정
- 이로 인해 학습 데이터 수가 줄어들고, 계산량이 대폭 감소
- 하지만 중요한 샘플(gradient 큰 데이터)은 유지 → 정확도 손상 거의 없음
5단계: 새로운 트리 생성
- 선택된 샘플을 기반으로 leaf-wise 방식으로 트리 생성
- (XGBoost는 level-wise)
- leaf-wise는 더 빠르게 손실 감소 → 적은 트리로 더 좋은 성능 가능
6단계: 모델 업데이트
- 전체 모델에 새로 만든 트리를 추가
7단계: 반복
- 잔차 재계산 → GOSS 샘플링 → 트리 생성 → 모델 업데이트
- 정해진 반복 횟수 또는 Early Stopping 조건 만족 시 종료
4. LightGBM 속도 비교



참고링크
https://en.wikipedia.org/wiki/LightGBM
[머신러닝] LightGBM
LightGBM의 개요와 hyper parameter에 대해 알아본다.
velog.io



