

민프
[AI | ML] LSTM(Long Short-Term Memory)이란? (Long Short-Term Memory 논문 리뷰) 본문
[AI | ML] LSTM(Long Short-Term Memory)이란? (Long Short-Term Memory 논문 리뷰)
민프야 2025. 5. 30. 23:00
LSTM이란?
LSTM(Long Short-Term Memory)은 순환신경망(RNN)의 일종으로,
기존 RNN이 갖고 있던 장기 의존성 문제를 해결하기 위해 제안된 구조입니다.
즉, 긴 문장이나 시퀀스에서도 기억을 잃지 않고 정보를 유지하면서 학습할 수 있도록 고안된 모델입니다.
왜 나왔을까?

자 먼저 위 논문에서 등장하는 Vanishing Gradient, Exploding Gradient
에 대해서 먼저 알아봅시다.
- Gradient(그래디언트)란?
딥러닝에서는 모델이 학습을 할 때,
오차(= loss)를 줄이기 위해 가중치(weight)를 얼마나 바꿔야 할지 결정합니다.
이때 사용하는 수치가 바로 gradient (그래디언트) 입니다.
즉, 경사도 또는 기울기입니다.
- 기존 RNN의 특징?
- RNN은 시퀀스 데이터(문장, 시간 흐름 등)를 처리합니다.
- “현재 시점”의 예측을 할 때, “과거 시점”의 정보도 함께 사용해야 하죠.
- 이를 위해 RNN은 시간을 따라 연결된 구조를 갖고,
- 역전파(Backpropagation Through Time, BPTT)라는 방식으로 학습합니다.
- 그런데 문제는?
시간이 길어지면(시퀀스가 길어지면)
그래디언트가 계속 곱해지고, 곱해지고, 곱해지게 됩니다.
이때 생기는 두 가지 문제가 아래 그래프와 같은
Vanishing Gradient, Exploding Gradient 입니다.

Vanishing Gradient Problem (그래디언트 소실 문제)
- 어떤 현상인가요?
- 계속 곱해지던 값이 0에 가까운 수면 -> 점점 작아져서 -> 거의 0이 됩니다.
- 결과
- 초반(과거) 시점의 정보는 거의 반영되지 않음
- 모델이 과거를 기억하지 못함
예시
- “나는 미국에서 살았다. 그래서 영어를 잘…”
-> “나는 미국에서 살았다”는 앞부분 정보가 중요한데 학습이 안 됨
Exploding Gradient Problem (그래디언트 폭발 문제)
- 어떤 현상인가요?
- 계속 곱해지던 값이 1보다 크면 -> 점점 커지고 -> 무한대로 발산
- 결과
- 그래디언트가 너무 커져서 가중치가 튀거나 NaN 발생
- 학습이 불안정하고, 수렴하지 않음
앞서 보여준 그래프 기억나시죠? 다시 한번 확인해보시면 아래와 같습니다.
- Vanishing Gradient → 그래디언트가 점점 0에 수렴
- Exploding Gradient → 그래디언트가 점점 무한대로 발산
왜 이런 일이 발생할까?

- 반복적으로 이전 은닉 상태 h_{t-1}에 weight 를 곱하면서 학습
- 이 weight가 1보다 작으면 계속 작아져서 vanishing
- 1보다 크면 계속 커져서 exploding
실질적인 결과는?
- RNN이 긴 문장을 이해하지 못함
- 예: “나는 어릴 적에 미국에서 살았는데 그래서 영어를 잘…” -> “합니다” 예측해야 하지만 “그래서” 이후 정보만 반영됨
- 장기적인 문맥 의존이 필요한 작업에서 완전 비효율
그래서 LSTM은?
- LSTM은 “셀 상태(cell state)”를 도입하여 정보를 직선으로 전달합니다.
- 그래디언트가 셀 상태를 따라 흐르면서 소실되지 않고 장기 정보를 유지할 수 있게 됩니다.
- 셀 상태에 게이트를 걸어서 “기억하고”, “지우고”, “업데이트하는” 메커니즘을 부여합니다.
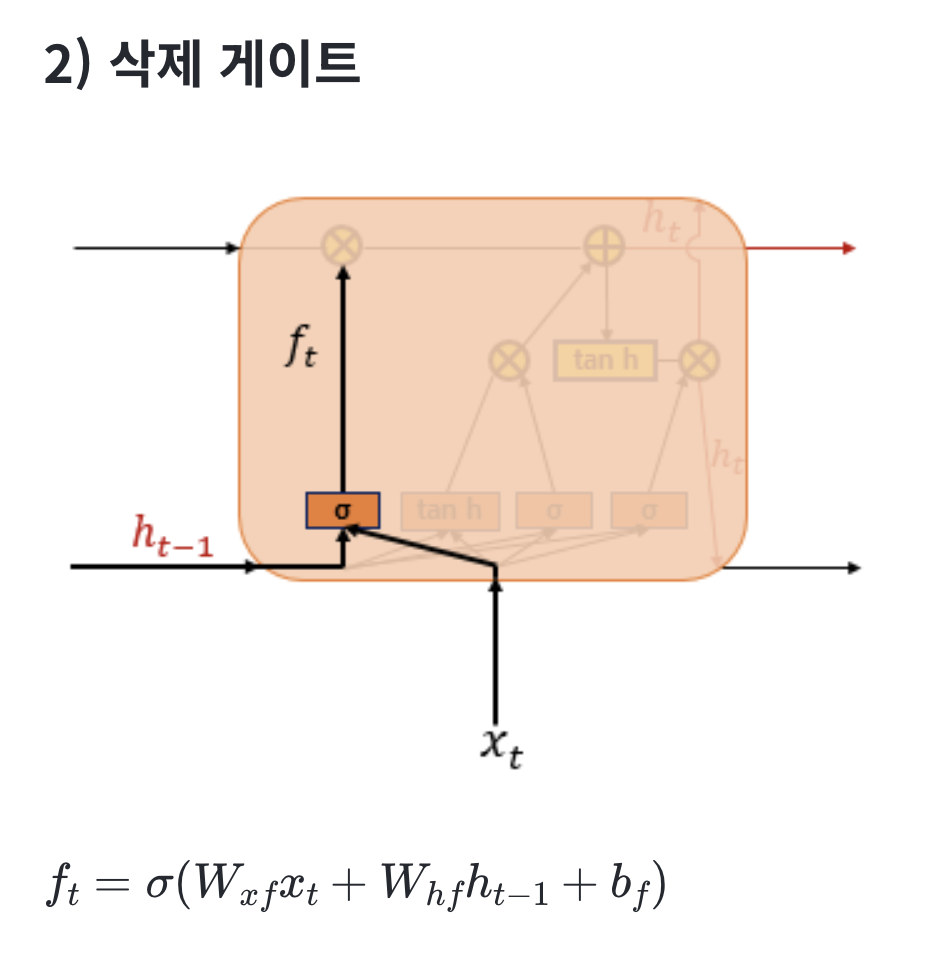
아래는 LSTM의 전체적인 내부의 모습을 보여줍니다.

| 구성 요소 | 설명 |
| x_t | 현재 입력 |
| h_{t-1} | 이전 시점의 hidden state (출력) |
| c_{t-1} | 이전 시점의 cell state (기억) |
| σ | 시그모이드 함수 -> 게이트 역할 (0~1) |
| ⊗ | 곱셈 (게이트와 정보의 조절) |
| ⊕ | 덧셈 (정보의 결합) |
| tanh | 하이퍼볼릭 탄젠트 함수 -> 값 범위 [-1, 1] |
| h_t | 현재 시점의 hidden state (출력) |
| c_t | 현재 시점의 cell state (업데이트된 기억) |
자 여기서 cell state란 무엇일까요
cell state란?
LSTM에서의 cell state는 그 구조의 핵심이자,
기존 RNN이 풀지 못했던 장기 기억(long-term memory) 문제를 해결한 핵심 요소입니다.
쉽게 말하면 아래와 같습니다.
- LSTM의 내부에 흐르는 정보 저장 통로입니다.
- LSTM은 매 시간 step마다 이 cell state를 조금씩 업데이트하거나 그대로 유지합니다.
- 이렇게 함으로써 기억하고 싶으면 기억하고, 잊고 싶으면 잊는 게이트 메커니즘을 적용할 수 있어요.

좀 더 자세하게 말하자면
셀 상태(Cell State)는 그림에서 왼쪽에서 오른쪽 으로 가는 굵은 선 입니다.
중앙의 굵은 선은 c_{t-1} \rightarrow c_t로 흘러가는 기억의 핵심 경로 이고,
⊗ 연산은 forget gate에 의해 기억 일부를 지우고,
⊕ 연산은 새로운 정보를 덧붙히게 됩니다.
이 그림은 LSTM의 핵심 철학인 다음을 잘 표현합니다:
“기억을 지우고, 새로 더하고, 잘 유지해라.”
- Cell state 수식으로 보기



Cell State는 주요 상태에 대한 수식들이 존재합니다.
여기에서 핵심은 3) 장기상태 입니다.
쉽게 말해서
- 과거의 기억 c_{t-1}는 forget gate f_t에 의해 일부 삭제되고,
- 새로 들어온 정보 gtt는 input gate i_t에 의해 일부 저장됩니다.
- 이 조합이 바로 지속적이면서도 선택적인 기억 조절 인 것 입니다.
쉬운 예시를 하나 들어보겠습니다.
- LSTM을 노트 앱이라 생각해볼까요?
- cell state는 노트 자체 입니다
- forget gate: 필요 없어진 메모를 지우는 기능
- input gate: 새로 추가할 메모를 받을지 말지 결정
- output gate: 이 노트의 일부를 화면에 보여줄지 말지
즉, cell state는 LSTM의 기억 저장소입니다.
실습 코드
마찬가지로 Jupyter Notebook으로 진행하였습니다.
RNN 실습 코드와 똑같은 데이터를 가지고 예측해보는 것을 해보겠습니다.


오.. 보면 그래도 요가 제일 높네요 ㅋㅋ..
데이터가 더 많았다면 RNN 보다 더 좋은 성능을 내지 않았을까 예상해봅니다.
참고링크
08-01 순환 신경망(Recurrent Neural Network, RNN)
RNN(Recurrent Neural Network)은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence) 모델입니다. 번역기를 생각해보면 입력은 번역하고자 하는 단어…
wikidocs.net
https://www.bioinf.jku.at/publications/older/2604.pdf
https://wegonnamakeit.tistory.com/7
[논문리뷰] RNN :: LSTM(Long Short Term Memory) 톺아보기
이 블로그 글은 딥러닝 공부를 목적으로, 최성준 박사님 강의와 여러 자료들을 참고하여 LSTM의 개념에 대해 정리하였습니다. 기존의 인공 신경망의 은닉층에는 맥락이 고려되지 않은 단순한 뉴
wegonnamakeit.tistory.com
[논문리뷰] Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling
Abstract 1. LSTM은 RNN 계열의 모델중 하나로 기존 RNN보다 temporal sequences, long-range dependecies에서 성능을 개선했다. temporal sequences: 시간에 따라 변하는 데이터의 순서 ex) 음성신호,
velog.io
https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE07252156
RNN과 LSTM을 이용한 주가 예측율 향상을 위한 딥러닝 모델 | DBpia
신동하, 최광호, 김창복 | 한국정보기술학회논문지 | 2017.10
www.dbpia.co.kr
https://medium.com/@nahcklee/lstm-%EC%A0%95%EB%A6%AC-1c116d7a9a36
LSTM(1997) 정리
원 논문 : Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735–1780.
medium.com
07-02 LSTM과 GRU
바닐라 아이스크림이 가장 기본적인 맛을 가진 아이스크림인 것처럼, 앞서 배운 RNN을 가장 단순한 형태의 RNN이라고 하여 바닐라 RNN(Vanilla RNN)이라고 합니다. (…
wikidocs.net



