
민프
[AI | ML][HPE] BlazePose에 대해서 알아보자 (BlazePose: On-device Real-time Body Pose tracking 논문 리뷰) 본문
[AI | ML][HPE] BlazePose에 대해서 알아보자 (BlazePose: On-device Real-time Body Pose tracking 논문 리뷰)
민프야 2023. 10. 16. 18:05오늘은 TensorFlow Lite에서 제공되는 MoveNet, PoseNet, BlazePose 중 BlazePose에 대해서 알아보겠습니다.
소개
BlazePose는 Google에서 개발된 기술로, 2021년에 TensorFlow.js에서 처음으로 3D 포즈 추정 모델로 소개되었습니다.
이 기술은 3D 모션 캡처, 캐릭터 애니메이션, 인체 포즈 추정 등 다양한 응용 분야에서 사용될 수 있습니다.

BlazePose는 Google의 MediaPipe 프레임워크를 통해 인체의 랜드마크를 감지하는 기술입니다.
이 기술은 이미지 또는 비디오에서 인간의 몸의 랜드마크를 감지하고 분석하는 데 사용됩니다.
MediaPipe Pose Landmarker는 실시간 비디오 피드, 디코드된 비디오 프레임, 정지 이미지 등
다양한 데이터 타입을 입력으로 받아 처리할 수 있습니다.
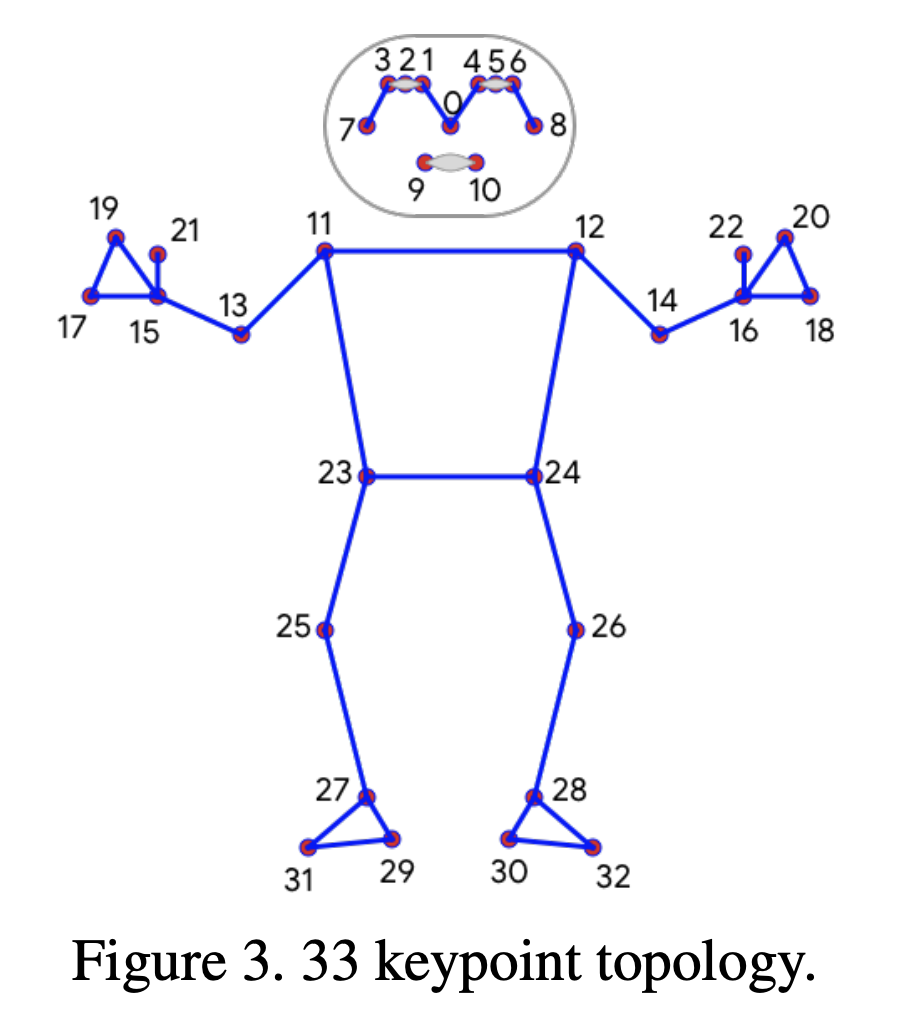
BlazePose는 33개의 바디 키포인트를 실시간으로 생성하며, 모바일 기기에서의 실시간 인퍼런스에 최적화되어 있습니다.
33개의 바디 키포인트 종류는 아래 사진과 같습니다.

그럼 포즈 추적의 추론 파이프라인은 어떻게 되는지 알아보겠습니다.
2.1 Inference pipeline
Pipline은 검출기(lightweight body pose detector), 추적기(Tracker) 구조로 이루어져있습니다.
아래 논문내용에 있는 파이프라인을 보며 각 구조에 대해서 설명해드리겠습니다.
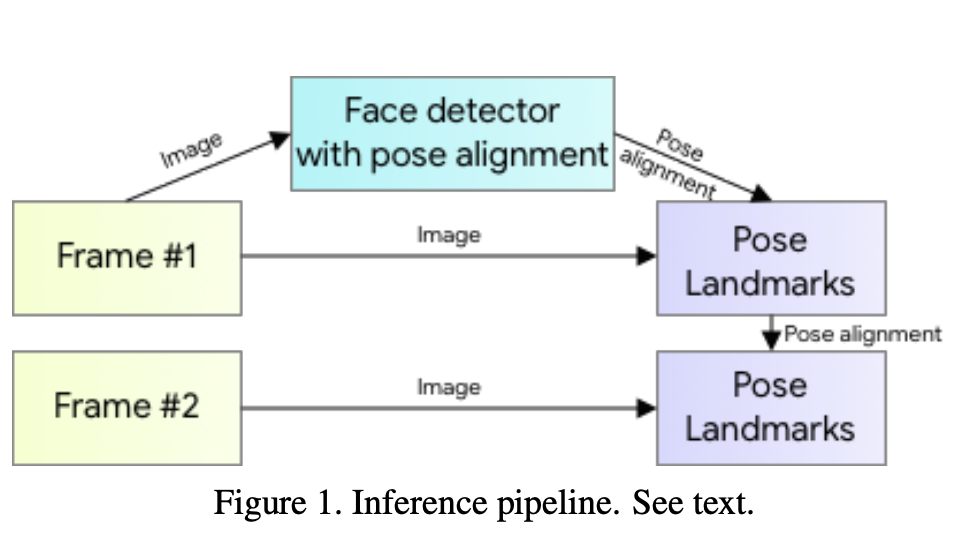
1. Frame #1
첫 번째 프레임은 비디오 또는 이미지 시퀀스의 시작점을 나타냅니다.
이 프레임은 초기 데이터 포인트로서, 포즈 검출기에 의해 분석되어 인체 포즈의 초기 추정을 제공합니다.
따라서 첫 번째 프레임이 캡처되면,
"Face Detector with Pose Alignment"이 이 프레임을 분석하여 인체의 얼굴과 포즈를 감지하고 정렬하여 ROI를 추출합니다.
(ROI는 포즈 추적 네트워크에 전달되어 신체의 초기 키포인트 추정하고 데이터로 저장하게 됩니다.)
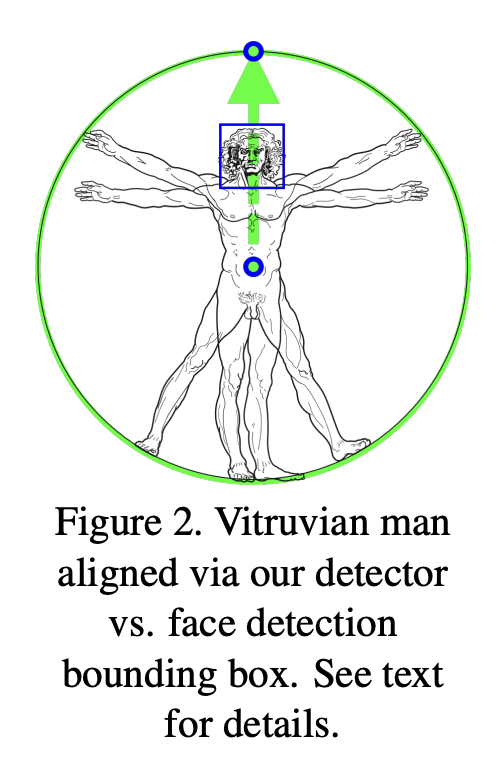
2. Face Detector with Pose Alignment (ROI 추출)
이 구성 요소는 인체의 얼굴을 감지하고 포즈를 정렬하는 역할을 합니다.
얼굴 검출기는 인체의 얼굴을 식별하고, 포즈 정렬은 인체의 포즈를 정확하게 추정합니다.
따라서 Frame #1이 주어지면,
이 구성 요소는 얼굴과 포즈를 감지하고 정렬하여 인체의 초기 포즈를 추정하여 ROI로 식별되고 추출됩니다.
좀더 자세하게 설명해드리자면
인체의 얼굴을 감지하고 포즈를 정렬하는 역할을 하게 되는데요
얼굴 검출기는 BlazeFace모델 사용하여 Faster R-CNN으로 인체의 얼굴을 식별하고, 포즈의 정렬은 인체 포즈를 추정합니다.
얼굴을 인식하게 되면 얼굴들의 키포인트를 기반으로 신체의 중심을 계산을 하고, Pose Alignment(자세 정렬)를 하게 됩니다.
Pose Alignment는 BlazeFace모델의 얼굴 검출 결과를 기반으로 인체의 중심을 정확히 설정하고 정렬 하는데에 목적을 두는데요.
tracker에 들어갈 사람 image의 sacle과 rotation을 보정하기 위해 사용됩니다.
Pose Alignment의 동작을 보면
첫번째로. BlazeFace에서 추출한 얼굴 키포인트(눈, 코, 입 등..)을 사용해 얼굴의 기울기를 계산하고,
이 기울기를 기반으로 이미지 전체를 회전하여, 얼굴과 신체의 주요 축이 화면이 y축과 평행하도록 조정합니다.
그다음 Scaling조정을 하게 되는데요
사진에서 주요 대상(사람 또는 얼굴)이 화면 중앙에 적절히 오도록 확대/축소를 하고
마지막으로 중심 정렬을하여 주요 대상을 화면의 중심에 배치하여 신체 모든 부분(특히 손, 발 머리 등..)을 안정적으로 포함할 수 있도록 합니다.
이러한 Pose Alignment을 통해 BlazePose은 모델이 안정적으로 인식할 수 있도록 회전도 보정되고, 다양한 사람의 크기에 관계없이 모델이 균일한 입력을 받을 수 있도록 합니다.
또한 얼굴을 중심으로 정렬된 이미지를 제공함으로써 속도 최적화의 강점을 얻을 수 있습니다.
3. Frame #2
두 번째 프레임은 이전 프레임(#1)의 ROI 및 자세 데이터를 기반으로 직접 Pose Landmarks 네트워크에서 처리되게 됩니다. 이렇게 하는 이유는 #1에서 계산된 ROI는 일반적으로 크게 변하지 않으므로 Face Detector를 매번 사용할 필요가 없어서 속도를 크게 향상 시킵니다.
따라서 #1에서 계산된 ROI와 자세 데이터를 #2의 시작점으로 사용하게 됩니다.
4. Pose Landmarks (33개의 Pose KeyPoint를 예측하는 구간)
Frame #2는 Frame #1의 키포인트 결과와 ROI를 분석하면서 인체의 33개 Pose KeyPoint 좌표를 실시간으로 예측하고 업데이트합니다.
따라서 인체의 동작과 포즈의 변화가 실시간으로 추적되고 분석됩니다.
좀더 자세하게 어떻게 Pose Landmarks Network가 동작하는지 아래 논문 내용의 이미지를 보며 말씀드려보자면
Face Detector with Pose Alignment에서 추출되고 정렬 된 ROI를 입력데이터로 받습니다.
해당 ROI의 이미지들에서 중요한 신체 특징을 추출해야하는데 이때 사용되는게 BlazeBlock이라는 효율적인 CNN 구조를 사용하여서 필요한 정보를 분석합니다.

위 사진에서 왼쪽부터 동작순서를 좀 보자면
- DW(Depthwise Convolution) Conv
- 입력 데이터(키포인트 결과와 ROI 이미지들..)에서 주요 특징을 추출합니다
- 결과는 1x1 Pointwise Convolution으로 전달됩니다.
- Max Pooling (Optional)
- 입력 데이터의 크기를 줄이고, 잔차 연결(Residual Connection) 경로로 전달됩니다.
- 크기 축소가 필요한 경우, Channel Padding을 통해 출력 크기를 맞춥니다.
- 1x1 Pointwise Convolution
- Depthwise Connection에서 추출된 정보와 채널 간 결합하여 피쳐맵을 생성합니다.
여기에서 일반적인 Conv와 DW Conv, PW Conv의 차이점을 말씀드려보자면
기본적으로 Conv은 CNN에서 사용되는 핵심 연간으로, 입력 이미지에서 특징(Edges, Patterns 등)을 추출합니다.
필터(또는 커널)가 입력 이미지를 이동하면서 연산을 수행하여 피처맵(Feature Map)을 생성합니다.
*피처맵은 각 이미지에서 판별(ex. 개 Or 고양이)될 수 있는 중요한 데이터를 말합니다.
여기에서
- Conv : 입력 데이터와 필터 간의 전체 연산을 수행합니다.
- DW Conv : 일반 Conv을 효율화한 연산으로, 각 입력 채널에 대해 독립적으로 필터를 적용합니다.
따라서 채널별로 독립적으로 작동하므로, 채널 간 관계 학습은 불가능하지만 채널 간 상효작용이 없으므로 연산량이 줄어드는 장점이 있습니다.
- PW Conv : 1x1 크기의 필터를 사용하여 채널 간의 정보를 결합하는 연산입니다.
공간 정보는 보존하지 않고, 채널 간 상호작용만 학습하는게 특징입니다.
따라서 연산량이 낮으면서도 채널 간의 관계를 학습이 가능하다는 장점이 있습니다.
비유를 해서 설명해드리자면
1. 일반 Convolution
• 모든 입력 채널을 동시에 사용하여 특징을 학습.
• 비유: 모든 채널을 한꺼번에 섞는 큰 믹서기.
2. Depthwise Convolution
• 각 채널을 독립적으로 처리.
• 비유: 채널별로 따로따로 섞는 작은 믹서기들.
3. Pointwise Convolution:
• 1x1 필터로 채널 간의 관계를 결합.
• 비유: 각각의 채널을 조합하여 새로운 믹스를 만드는 과정.
결론적으로 Depthwise + Pointwise Convolution의 조합은
일반 Convolution은 가장 강력하지만 연산량이 높은 부분을 더 경량화하기 위해 나왔고 이러한 방법은 MobileNet와 같은 경량화 모델에서 실제 사용됩니다.
Depthwise Convolution은 효율성을 극대화하지만, 채널 간 상호작용은 학습하지 못하는 단점을
Pointwise Convolution을 사용하여 채널 간 상호작용을 효율적으로 학습하며, Depthwise와 결합하여 경량화 모델에서 뛰어난 성능을 발휘하도록 만드는 조합입니다.
4. Channel Padding (Optional)
- 입력 데이터와 출력 데이터의 채널 크기를 맞추기 위해 사용됩니다.
5. Residual Connection (잔차 연결)
- 입력 데이터를 출력으로 바로 연결하여 학습 안정성을 높이고, 정보 손실을 방지합니다.
6. Activation (활성화 함수)
- 일반적으로 ReLU와 같은 활성화 함수가 사용되는 구간입니다.
오른쪽 부분을 보면
Double BlazeBlock은 BlazeBlock의 확장형으로, 더 많은 연산 단계를 추가하여 더 넓은 리셉티브 필드와 깊은 특징 추출을 지원합니다. 다음과 같은 추가 단계가 포함됩니다
(*리셉티브 필드란 CNN에서 뉴런이 입력 이미지에서 관찰할 수 있는 영역 입니다.)
위에서 설명한 내용들은 스킵하고 넘어가도록 하겠습니다.
여기에서 새로 보이는 부분은
- 1x1 Pointwise Convolution / Project
- 1x1 Pointwise Convolution / Expand
인데요
기존에 1x1 Pointwise Convolution을 설명해드릴때
"채널 간 연산을 통해 새로운 피처맵을 생성하는 것"이라고 설명해드렸는데
그럼 이것과 어떻게 다른지에 대해서 말씀드려보겠습니다.
| 항목 | 1x1 Pointwise Convolution | 1x1 Pointwise Convolution / Project | 1x1 Pointwise Convolution / Expand |
| 역할 | 채널 간 상호작용 학습 | 채널 수를 줄여 데이터 압축 | 채널 수를 늘려 표현력 강화 |
| 채널 변환 | 새로운 채널 생성 | 채널 크기를 축소 | 채널 크기 확장 |
| 목적 | 일반적인 채널 간 정보 결합 | 연산량 감소, 중요한 정보만 유지 | 모델의 표현력을 강화 |
| 주요 사용 시점 | 전반적인 피처맵 변환에 사용 | 데이터를 효율적으로 압축할 때 사용 | 고수준 표현을 학습해야 할 때 사용 |
| 활용 예 | 피처맵 간 변환 | Depthwise Convolution 이후 | 깊은 네트워크에서 추가 특징 학습 |
정리하면 위 테이블과 같습니다.
좀 더 쉽게 정리해드려보면
1. 1x1 Pointwise Convolution
- 입력 데이터를 채널 단위로 처리하여 새로운 채널 데이터를 생성.
- 입력 데이터의 채널 크기와 출력 데이터의 채널 크기는 사용자 설정에 따라 다름
2. 1x1 Pointwise Convolution / Project
- 채널 수를 줄이기 위해 사용되며, 중요하지 않은 정보를 제거합니다.
- Depthwise Convolution 전에 사용되어 연산량을 감소시키고, 데이터 크기를 줄임.
3. 1x1 Pointwise Convolution / Expand
- 채널 수를 늘리기 위해 사용되며, 모델의 학습 표현력을 강화합니다.
- Depthwise Convolution 후에 사용되어, 압축된 데이터를 풍부한 표현으로 변환.
자 그럼 본격적으로 double BlazeBlock 과정을 말씀드려보겠습니다.
1. 5x5 Depthwise Convolution (첫 번째)
- 첫 번째 Depthwise Convolution은 기본 BlazeBlock과 동일하게 주요 패턴을 감지합니다.
2. 1x1 Pointwise Convolution / Project
-첫 번째 Pointwise Convolution에서 채널 크기를 줄이며, 중요 정보를 압축합니다.
3. 5x5 Depthwise Convolution (두 번째)
- 두 번째 Depthwise Convolution은 첫 번째에서 추출된 피처를 더 넓은 리셉티브 필드로 확장합니다.
(*리셉티크 필드가 확장 된다는 건 작은 창문을 통해 관찰하는 것과, 넓은 창문을 통해 더 큰 영역을 관찰하는 것을 의미합니다.)
4. 1x1 Pointwise Convolution / Expand
- 채널 크기를 확장하여 표현력을 추가합니다.
여기에서 표현력을 추가한다는 건 채널 크기를 확장하니 당연히 이미지의 텍스쳐, 윤곽선, 색상 등과 같은 다양한 특징을 각각의 채널에 학습을 할 수 있습니다.
5. Residual Connection (잔차 연결)
- BlazeBlock과 동일하게 입력 데이터를 출력에 더합니다.
6. Max Pooling & Channel Padding (Optional)
- 필요 시 피처맵의 크기와 채널을 조정합니다.
7. Activation (활성화 함수)
- 각 Pointwise Convolution 이후에 활성화 함수가 적용됩니다.
이렇게 하여 최종적으로 피처맵 (feature map)을 생성합니다.
추출 된 피처맵을 통해 이후 아래에 나오는 NNA - Heatemap, offeset, Regression으로
2.2. Person Detector
현대의 객체 검출 솔루션은 Non-Maximum Suppression (NMS) 알고리즘에 의존하는데,
이는 인간의 고도로
구조화된 포즈(포옹이나 악수 같은 KeyPoint가 겹치는 동작들)에는 오작동이 일어난다는 한계점이 존재했습니다.
이러한 한계를 극복하기 위해,
본 논문에서는 인체의 얼굴이나 상반신 같은 상대적으로 강체에 가까운 부분의 경계 상자를 검출하는 데 중점을 둡니다.
얼굴은 고대비 특징을 가지고 있고 외관의 변화가 적기 때문에 신경망에 강한 신호를 제공합니다
인간의 얼굴은 명확한 Feature가 있고, 상대적으로 편차가 적다는 장점이 있어서 Detector의 기준을 얼굴로 정했습니다.
결론적으로는 Face Detector를 사용하여 사람을 감지한다는 것 입니다.
Face Detector로는 BlazeFace를 이용해서 사람의 머리가 항상 보이는 Single Person 사례를 가정합니다.
사람의 골반 중앙값, 사람을 포함하는 원의 크기, 사람의 기울기,
그리고 중앙 어깨와 중앙 엉덩이 지점을 연결하는 선의 각도 등 추가적인 파라미터를 예측하였습니다.
2.3. Topology
Topology는 어떤 구조와 구조간의 연결을 나타나는 것을 의미하는데,
이 토폴로지는 인체의 33개의 특정 부위와 그 부위들 간의 관계를 나타냅니다.
따라서 BlazePose는 BlazeFace, BlazePalm, Coco 데이터셋의 키포인트를 통합하여
33개의 키포인트 토폴로지를 구성합니다
이전에 2.1 Inference pipeline - 4. Pose Landmarks 구간에서 33개의 KeyPoint를 찾는다고 했는데
이 토폴로지의 구조가 Pose Landmarks 단계에서 키포인트의 실제 위치를 예측하는 데 사용되는 기반 구조를 제공합니다.
2.4. Dataset
히트맵을 사용하여 키포인트를 감지하는 기존 자세 추정 솔루션의 대부분과 비교할 때,
추적 기반 솔루션(tracking based solution)에는 초기 자세 정렬(initial pose alignment)이 필요합니다.
따라서
BlazePose의 데이터셋은 60K의 이미지로 구성되어 있으며,
이 이미지들은 일반적인 포즈와 동작을 수행하는 한 명 또는 소수의 사람들을 포함하고 있습니다.
또한, 25K의 이미지는 한 명의 사람이 피트니스 운동을 수행하는 장면을 포함하고 있습니다.
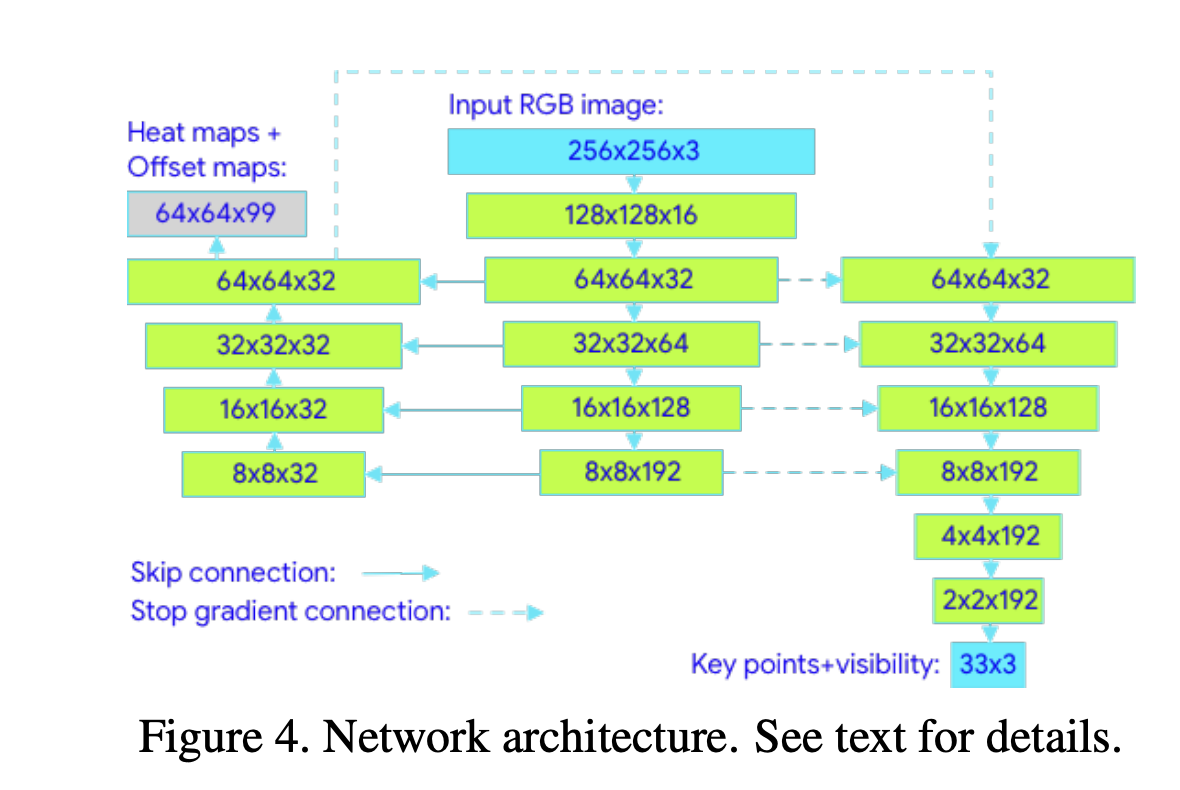
2.5. Neural Network Architecture

BlazePose의 NNA를 보면 Heatmap, Offset, and Regression를 결합하여 사용된 것을 확인할 수 있고,
결론적으로 pose estimation component를 사용하여 33개의 인체 키포인트 위치를 예측할 수 있게 되었습니다.
예를 들어서) 사람이 카메라 앞에서 서있을 때,
이 컴포넌트는 각 키포인트(예: 머리, 손목, 무릎 등)의 위치를 식별하고 추적하는 것을 의미합니다.
1. Input RGB Image
사람의 이미지가 네트워크 입력으로 사용됩니다.
2. Heatmap, Offset, and Regression
입력 이미지를 Heatmap, Offset 사용하여 키포인트의 위치를 학습하고,
이 정보를 바탕으로 regression encoder 네트워크를 통해 키포인트의 정확한 위치를 예측합니다.
쉽게 말해서
히트맵은 키포인트의 근사 위치를,
오프셋은 키포인트의 정확한 위치를,
regression encoder는 키포인트 간의 관계를 예측합니다.
더 쉽게 말해서
히트맵은 사람의 머리가 이미지의 어느 부분에 있는지를 근사적으로 나타내고,
오프셋은 그 위치를 미세 조정하여 정확하게 만들게 됩니다.
여기에서 Heatmap은 어떠한 객체 위치, 객체를 예측하는데 다양한 방식 중 하나입니다.
쉽게 말해 2D맵 형태로, 이미지에서 원하는 객체가 있을법한 확률 분포를 색상으로 나타내는데 값이 높은 위치(따뜻한 색상)는 해당 객체/키포인트가 있을 가능성이 높습니다.
이걸 거치고 나면 원본 이미지보다 저해상도로 생성되어 계산 효율성을 높히게 됩니다.
Offset도 추가적으로 말씀드려보면 Heatmap의 저해상도로 인해 발생되는 위치 정확도 손실을 보완하기 위해 사용됩니다.
따라서 Heatmap이 특정 객체/키포인트의 근사 위치를 제공한다면, Offset은 해당 위치를 보정하여서 정확한 위치를 계산합니다.
이렇게 Offset과 Heatmap은 함께 사용되고, Heatmap 상의 픽셀 단위 오차를 줄이는데 사용됩니다.
위 방식은 Newell의 Stacked Hourglass에 영감을 받았다고 나오는데 그럼 어떤 부분을 영감을 받은 것 일까요?
Stacked Hourglass에 대해서는 이전 포스팅에서 다뤄본적이 있는데
간단하게 Stacked Hourglass에 대해서 말해보자면
Input이미지가 들어오면
이미지를 다운스케일을 하여서 저해상도에서의 특징을 추출하고,
다시 업스케일을 하여서 고해상도에서의 세부 정보를 캡쳐합니다.
이 과정이 반복되면서 hourglass 형태의 구조가 만들어지게 되고,
이미지의 다양한 크기와 형태의 특징을 동시에 학습할 수 있는 방법을 의미합니다.
BlazePose는 다운스케일, 업스케일, 반복적인 과정에 영감을 받아서 그 과정을
히트맵, 오프셋, 회귀 방법으로 만들어서 예측하는 방식을 만들었습니다.
비교해보자면 아래와 같습니다.
Stacked Hourglass
다운스케일: 이미지의 해상도를 낮춰 저해상도에서의 전반적인 특징을 추출합니다.
업스케일: 이미지의 해상도를 높여 고해상도에서의 세부 정보를 캡쳐합니다.
반복적인 과정: 이러한 다운스케일과 업스케일 과정을 여러 번 반복하여 이미지의 다양한 스케일에서 특징을 학습합니다.
BlazePose
히트맵: 키포인트의 근사적 위치를 학습하는 데 사용됩니다.
오프셋: 히트맵으로 얻은 근사적 위치를 미세 조정하여 정확한 위치를 얻습니다.
회귀: 키포인트 간의 공간적 관계와 구조를 학습합니다.
위 비교와 같이 BlazePose는 Stacked Hourglass의 다운스케일과 업스케일 과정을 사용하지 않고,
히트맵과 오프셋을 결합한 회귀 접근법으로
계산 효율성과 속도를 최적화하는 데 중점을 둔 설계하여 키포인트의 위치와 구조를 예측하였습니다.
내용들을 정리를 해보자면
2.1 Inference Pipeline - 4. Pose Landmarks 33개의 Pose KeyPoint를 예측하는 구간에서
2.3 Topology를 기반으로 한 Figure 4의 네트워크 아키텍처에서 33개의 KeyPoint를 예측합니다.
3. Experiments
이 섹션에서는 BlazePose 모델의 품질을 평가하기 위해 OpenPose를 기준으로 사용했습니다.
이를 위해 연구자들은 1-2명의 사람이 있는 1000개의 이미지로 구성된 두 개의 내부 데이터셋을 수동으로 주석을 달았습니다.
데이터 셋으로는
- AR 데이터셋: 다양한 인간의 포즈를 포함하고 있습니다.
- 요가/피트니스 데이터셋: 요가와 피트니스 포즈만 포함하고 있습니다.
평가지표로는
PCK@0.2 (Percent of Correct Points with 20% tolerance)를 사용하였고,
두 명의 주석자가 AR 데이터셋을 독립적으로 재주석을 달아 평균 PCK@0.2가 97.2를 얻었습니다.
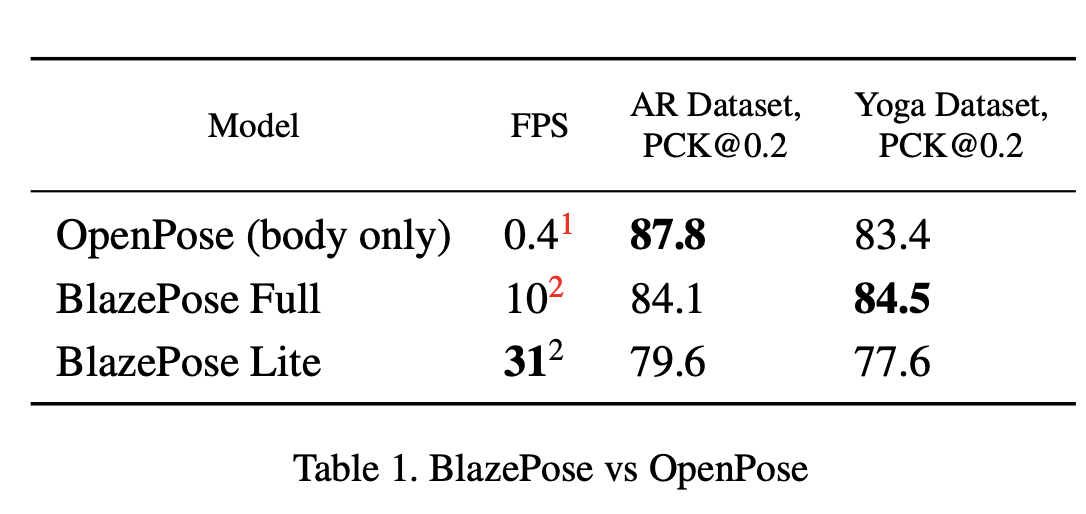
결론적으로
BlazePose 모델은 AR 데이터셋에서 OpenPose 모델보다 약간 낮은 성능을 보였지만,
요가/피트니스 사용 사례에서는 OpenPose를 능가했습니다.
또 속도는 25~75배 더 빠르다는 것을 확인할 수 있습니다.
4. Applications
BlazePose는 실시간 성능과 다양한 응용 분야를 위해 개발되었습니다.
모델은 모바일 장치에서 효율적으로 작동하며, 특정 키포인트 토폴로지와 함께 사용될 때 추가적인 이점을 제공합니다.
BlazePose는 히트맵/오프셋 맵에 의존하지 않아, 더 많은 키포인트와 3D 지원 등으로 확장하는 데 유리합니다.
참고링크
https://arxiv.org/pdf/1907.05047
https://developers.google.com/mediapipe/solutions/vision/pose_landmarker
https://arxiv.org/pdf/2006.10204.pdf
https://blog.tensorflow.org/2021/08/3d-pose-detection-with-mediapipe-blazepose-ghum-tfjs.html
https://velog.io/@hanlyang0522/Blazepose-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0



