
민프
[AI | ML][HPE] BlazePose에 대해서 알아보자 (BlazePose: On-device Real-time Body Pose tracking 논문 리뷰) 본문
[AI | ML][HPE] BlazePose에 대해서 알아보자 (BlazePose: On-device Real-time Body Pose tracking 논문 리뷰)
민프야 2023. 10. 16. 18:05오늘은 TensorFlow Lite에서 제공되는 MoveNet, PoseNet, BlazePose 중 BlazePose에 대해서 알아보겠습니다.
소개
BlazePose는 Google에서 개발된 기술로, 2021년에 TensorFlow.js에서 처음으로 3D 포즈 추정 모델로 소개되었습니다.
이 기술은 3D 모션 캡처, 캐릭터 애니메이션, 인체 포즈 추정 등 다양한 응용 분야에서 사용될 수 있습니다.

BlazePose는 Google의 MediaPipe 프레임워크를 통해 인체의 랜드마크를 감지하는 기술입니다.
이 기술은 이미지 또는 비디오에서 인간의 몸의 랜드마크를 감지하고 분석하는 데 사용됩니다.
MediaPipe Pose Landmarker는 실시간 비디오 피드, 디코드된 비디오 프레임, 정지 이미지 등
다양한 데이터 타입을 입력으로 받아 처리할 수 있습니다.
BlazePose는 33개의 바디 키포인트를 실시간으로 생성하며, 모바일 기기에서의 실시간 인퍼런스에 최적화되어 있습니다.
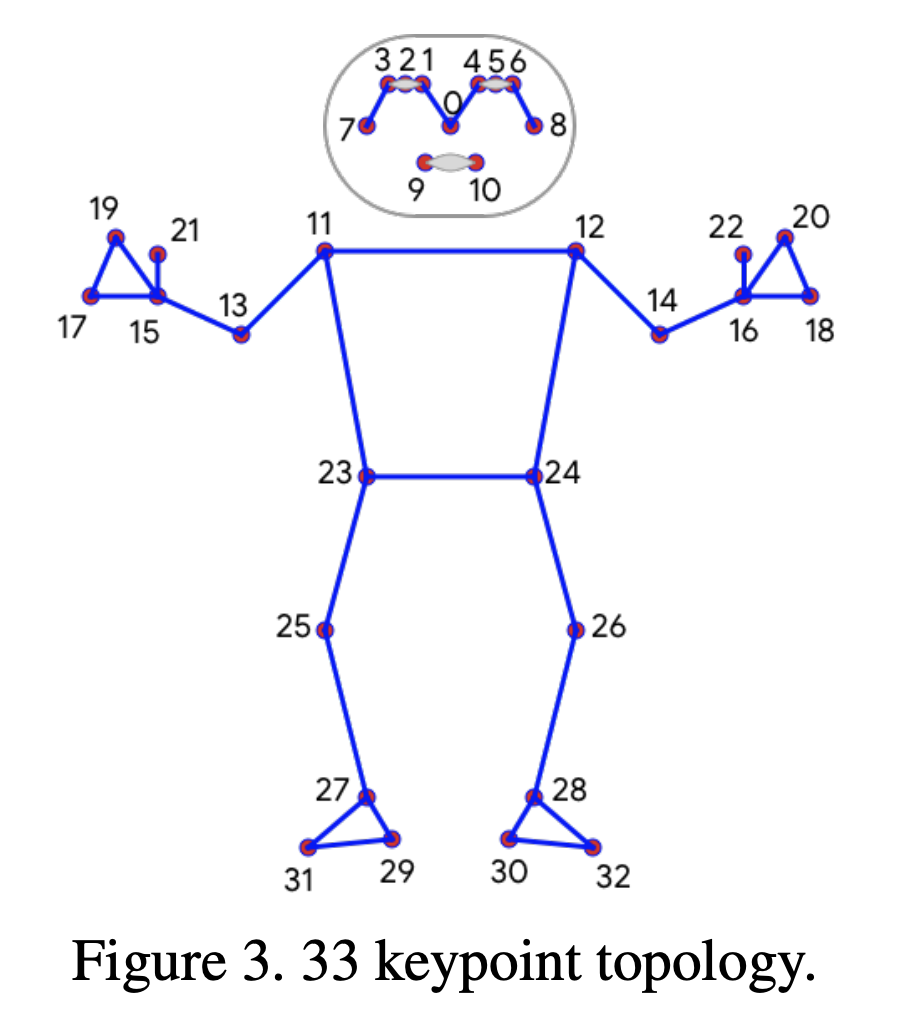
33개의 바디 키포인트 종류는 아래 사진과 같습니다.

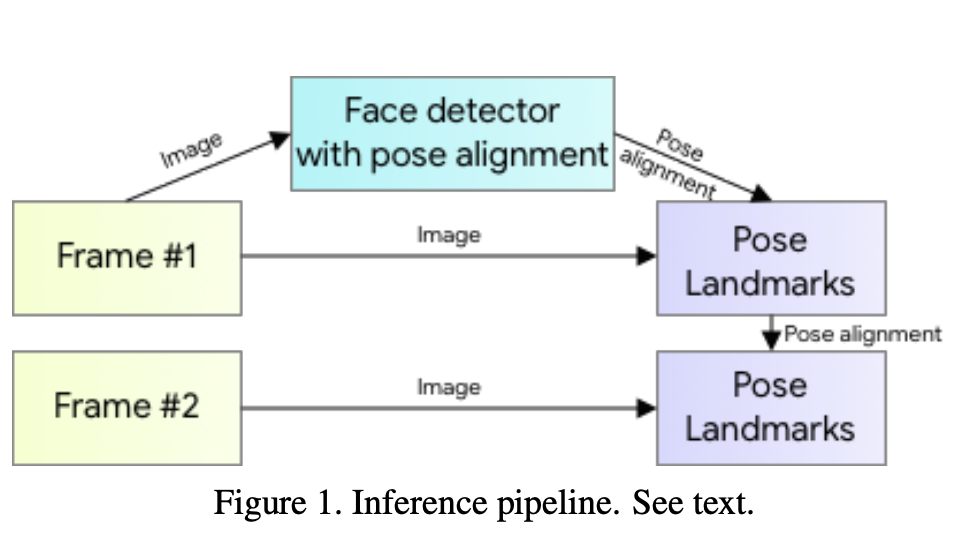
그럼 포즈 추적의 추론 파이프라인은 어떻게 되는지 알아보겠습니다.
2.1 Inference pipeline
Pipline은 검출기(lightweight body pose detector), 추적기(Tracker) 구조로 이루어져있습니다.
각 구조에 대해서 설명해드리겠습니다.
1. Frame #1
첫 번째 프레임은 비디오 또는 이미지 시퀀스의 시작점을 나타냅니다.
이 프레임은 초기 데이터 포인트로서, 포즈 검출기에 의해 분석되어 인체 포즈의 초기 추정을 제공합니다.
따라서 첫 번째 프레임이 캡처되면,
"Face Detector with Pose Alignment"이 이 프레임을 분석하여 인체의 얼굴과 포즈를 감지하고 정렬합니다.
2. Face Detector with Pose Alignment (ROI 추출)
이 구성 요소는 인체의 얼굴을 감지하고 포즈를 정렬하는 역할을 합니다.
얼굴 검출기는 인체의 얼굴을 식별하고, 포즈 정렬은 인체의 포즈를 정확하게 추정합니다.
따라서 Frame #1이 주어지면,
이 구성 요소는 얼굴과 포즈를 감지하고 정렬하여 인체의 초기 포즈를 추정하여 ROI로 식별되고 추출됩니다.
3. Frame #2
두 번째 프레임은 시간 경과와 함께 캡처된 연속 프레임입니다.
따라서 이 프레임은 포즈 추적 네트워크에 의해 분석되어 인체의 동작과 포즈의 변화를 실시간으로 추적합니다.
4. Pose Landmarks (33개의 Pose KeyPoint를 예측하는 구간)
Frame #2를 분석하면서 인체의 33개 Pose KeyPoint 좌표를 실시간으로 예측하고 업데이트합니다.
따라서 인체의 동작과 포즈의 변화가 실시간으로 추적되고 분석됩니다.
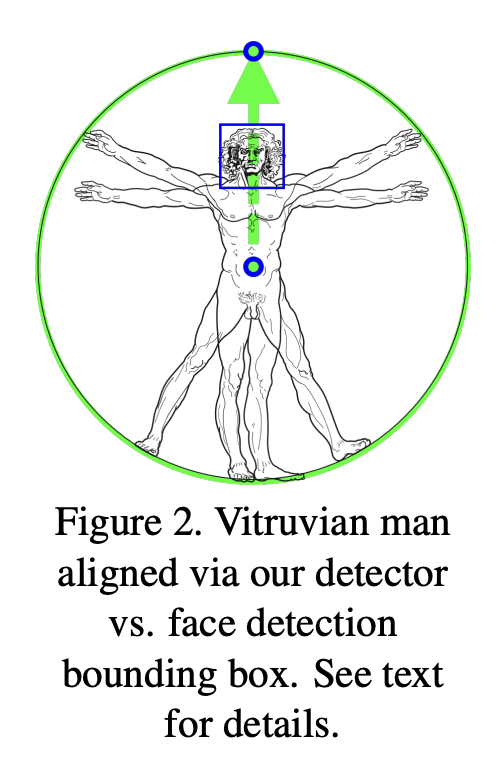
2.2. Person Detector
현대의 객체 검출 솔루션은 Non-Maximum Suppression (NMS) 알고리즘에 의존하는데,
이는 인간의 고도로
구조화된 포즈(포옹이나 악수 같은 KeyPoint가 겹치는 동작들)에는 오작동이 일어난다는 한계점이 존재했습니다.
이러한 한계를 극복하기 위해,
본 논문에서는 인체의 얼굴이나 상반신 같은 상대적으로 강체에 가까운 부분의 경계 상자를 검출하는 데 중점을 둡니다.
얼굴은 고대비 특징을 가지고 있고 외관의 변화가 적기 때문에 신경망에 강한 신호를 제공합니다
인간의 얼굴은 명확한 Feature가 있고, 상대적으로 편차가 적다는 장점이 있어서 Detector의 기준을 얼굴로 정했습니다.
결론적으로는 Face Detector를 사용하여 사람을 감지한다는 것 입니다.
Face Detector로는 BlazeFace를 이용해서 사람의 머리가 항상 보이는 Single Person 사례를 가정합니다.
사람의 골반 중앙값, 사람을 포함하는 원의 크기, 사람의 기울기,
그리고 중앙 어깨와 중앙 엉덩이 지점을 연결하는 선의 각도 등 추가적인 파라미터를 예측하였습니다.
2.3. Topology
Topology는 어떤 구조와 구조간의 연결을 나타나는 것을 의미하는데,
이 토폴로지는 인체의 33개의 특정 부위와 그 부위들 간의 관계를 나타냅니다.
따라서 BlazePose는 BlazeFace, BlazePalm, Coco 데이터셋의 키포인트를 통합하여
33개의 키포인트 토폴로지를 구성합니다
이전에 2.1 Inference pipeline - 4. Pose Landmarks 구간에서 33개의 KeyPoint를 찾는다고 했는데
이 토폴로지의 구조가 Pose Landmarks 단계에서 키포인트의 실제 위치를 예측하는 데 사용되는 기반 구조를 제공합니다.
2.4. Dataset
히트맵을 사용하여 키포인트를 감지하는 기존 자세 추정 솔루션의 대부분과 비교할 때,
추적 기반 솔루션(tracking based solution)에는 초기 자세 정렬(initial pose alignment)이 필요합니다.
따라서
BlazePose의 데이터셋은 60K의 이미지로 구성되어 있으며,
이 이미지들은 일반적인 포즈와 동작을 수행하는 한 명 또는 소수의 사람들을 포함하고 있습니다.
또한, 25K의 이미지는 한 명의 사람이 피트니스 운동을 수행하는 장면을 포함하고 있습니다.
2.5. Neural Network Architecture
BlazePose의 NNA를 보면 Heatmap, Offset, and Regression를 결합하여 사용된 것을 확인할 수 있고,
결론적으로 pose estimation component를 사용하여 33개의 인체 키포인트 위치를 예측할 수 있게 되었습니다.
예를 들어서) 사람이 카메라 앞에서 서있을 때,
이 컴포넌트는 각 키포인트(예: 머리, 손목, 무릎 등)의 위치를 식별하고 추적하는 것을 의미합니다.
1. Input RGB Image
사람의 이미지가 네트워크 입력으로 사용됩니다.
2. Heatmap, Offset, and Regression
입력 이미지를 Heatmap, Offset 사용하여 키포인트의 위치를 학습하고,
이 정보를 바탕으로 regression encoder 네트워크를 통해 키포인트의 정확한 위치를 예측합니다.
쉽게 말해서
히트맵은 키포인트의 근사 위치를,
오프셋은 키포인트의 정확한 위치를,
regression encoder는 키포인트 간의 관계를 예측합니다.
더 쉽게 말해서
히트맵은 사람의 머리가 이미지의 어느 부분에 있는지를 근사적으로 나타내고,
오프셋은 그 위치를 미세 조정하여 정확하게 만들게 됩니다.
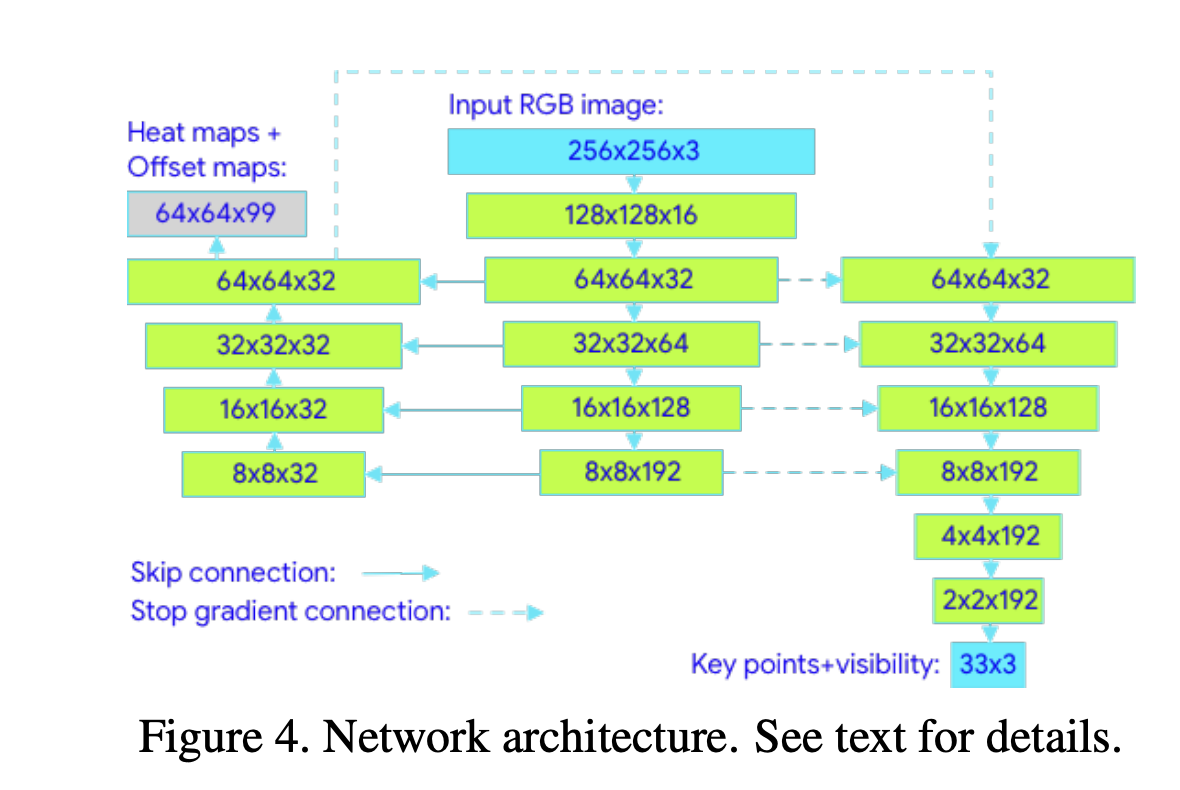
위 방식은 Newell의 Stacked Hourglass에 영감을 받았다고 나오는데 그럼 어떤 부분을 영감을 받은 것 일까요?
Stacked Hourglass에 대해서는 이전 포스팅에서 다뤄본적이 있는데
간단하게 Stacked Hourglass에 대해서 말해보자면
Input이미지가 들어오면
이미지를 다운스케일을 하여서 저해상도에서의 특징을 추출하고,
다시 업스케일을 하여서 고해상도에서의 세부 정보를 캡쳐합니다.
이 과정이 반복되면서 hourglass 형태의 구조가 만들어지게 되고,
이미지의 다양한 크기와 형태의 특징을 동시에 학습할 수 있는 방법을 의미합니다.
BlazePose는 다운스케일, 업스케일, 반복적인 과정에 영감을 받아서 그 과정을
히트맵, 오프셋, 회귀 방법으로 만들어서 예측하는 방식을 만들었습니다.
비교해보자면 아래와 같습니다.
Stacked Hourglass
다운스케일: 이미지의 해상도를 낮춰 저해상도에서의 전반적인 특징을 추출합니다.
업스케일: 이미지의 해상도를 높여 고해상도에서의 세부 정보를 캡쳐합니다.
반복적인 과정: 이러한 다운스케일과 업스케일 과정을 여러 번 반복하여 이미지의 다양한 스케일에서 특징을 학습합니다.
BlazePose
히트맵: 키포인트의 근사적 위치를 학습하는 데 사용됩니다.
오프셋: 히트맵으로 얻은 근사적 위치를 미세 조정하여 정확한 위치를 얻습니다.
회귀: 키포인트 간의 공간적 관계와 구조를 학습합니다.
위 비교와 같이 BlazePose는 Stacked Hourglass의 다운스케일과 업스케일 과정을 사용하지 않고,
히트맵과 오프셋을 결합한 회귀 접근법으로
계산 효율성과 속도를 최적화하는 데 중점을 둔 설계하여 키포인트의 위치와 구조를 예측하였습니다.
내용들을 정리를 해보자면
2.1 Inference Pipeline - 4. Pose Landmarks 33개의 Pose KeyPoint를 예측하는 구간에서
2.3 Topology를 기반으로 한 Figure 4의 네트워크 아키텍처에서 33개의 KeyPoint를 예측합니다.
3. Experiments
이 섹션에서는 BlazePose 모델의 품질을 평가하기 위해 OpenPose를 기준으로 사용했습니다.
이를 위해 연구자들은 1-2명의 사람이 있는 1000개의 이미지로 구성된 두 개의 내부 데이터셋을 수동으로 주석을 달았습니다.
데이터 셋으로는
- AR 데이터셋: 다양한 인간의 포즈를 포함하고 있습니다.
- 요가/피트니스 데이터셋: 요가와 피트니스 포즈만 포함하고 있습니다.
평가지표로는
PCK@0.2 (Percent of Correct Points with 20% tolerance)를 사용하였고,
두 명의 주석자가 AR 데이터셋을 독립적으로 재주석을 달아 평균 PCK@0.2가 97.2를 얻었습니다.
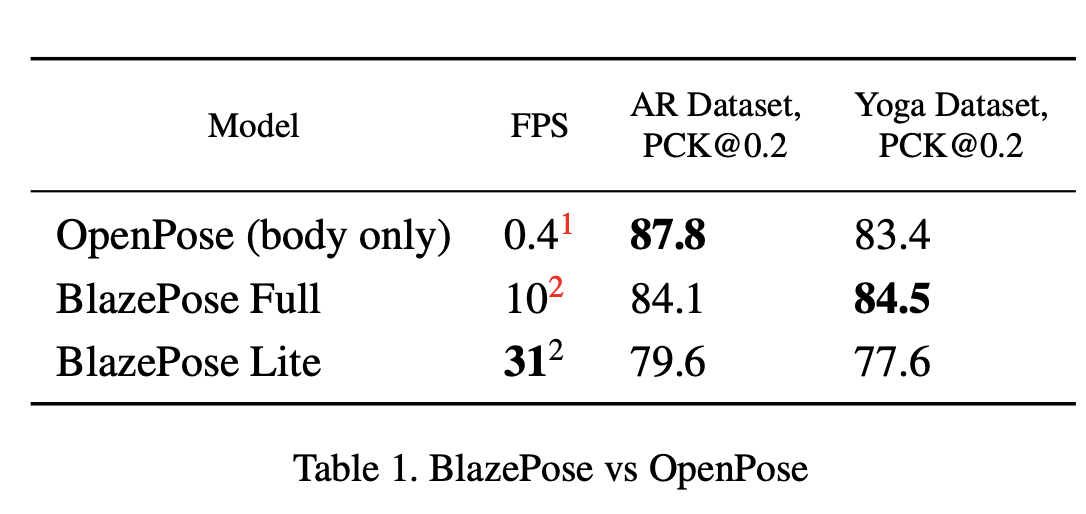
결론적으로
BlazePose 모델은 AR 데이터셋에서 OpenPose 모델보다 약간 낮은 성능을 보였지만,
요가/피트니스 사용 사례에서는 OpenPose를 능가했습니다.
또 속도는 25~75배 더 빠르다는 것을 확인할 수 있습니다.
4. Applications
BlazePose는 실시간 성능과 다양한 응용 분야를 위해 개발되었습니다.
모델은 모바일 장치에서 효율적으로 작동하며, 특정 키포인트 토폴로지와 함께 사용될 때 추가적인 이점을 제공합니다.
BlazePose는 히트맵/오프셋 맵에 의존하지 않아, 더 많은 키포인트와 3D 지원 등으로 확장하는 데 유리합니다.
참고링크
https://developers.google.com/mediapipe/solutions/vision/pose_landmarker
https://arxiv.org/pdf/2006.10204.pdf
https://blog.tensorflow.org/2021/08/3d-pose-detection-with-mediapipe-blazepose-ghum-tfjs.html
https://velog.io/@hanlyang0522/Blazepose-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0



