
민프
[AI | ML][ML][GBDT] GBDT(Gradient Boosting Decision Tree)에 대해서 알아보자 (Feat. Boosting) 본문
[AI | ML][ML][GBDT] GBDT(Gradient Boosting Decision Tree)에 대해서 알아보자 (Feat. Boosting)
민프야 2025. 5. 7. 15:341. GBDT란?
GBDT는 Gradient Boosting Decision Tree의 약자로,
여러 개의 결정 트리(Decision Tree)를 순차적으로 학습하여 예측 성능을 향상시키는 앙상블 기법입니다.
약한 학습기(weak learner)인 결정 트리를 하나씩 추가하면서,
이전 모델의 오차를 줄이기 위해 점점 더 나은 모델을 만드는 방식입니다.
2. GBDT는 언제 필요한가? 왜 필요한가?
단일 Decision Tree의 한계는 아래와 같이 분명합니다.
- 과적합 또는 과소적합
- 일반화 성능 부족
따라서 이 문제를 해결해주는 부스팅 Boosting 이라는 알고리즘을 사용합니다.
- 여러 트리를 순차적으로 학습
- 이전 모델이 틀린 부분을 다음 모델이 집중해서 학습
- 최종적으로 예측을 합쳐서 강한 학습기(strong learner)를 만들게 됨
2-1. 부스팅이란?
간단하게 부스팅에 대한 개념을 잡고 가보겠습니다.
머신러닝을 공부하다 보면 “부스팅(boosting)“이라는 용어를 자주 접하게 됩니다.
이 단어가 낯설게 느껴질 수 있지만, 사실은 아주 직관적인 아이디어에서 시작된 개념입니다.
한문장으로 요약하자면 아래와 같습니다.
부스팅은 ‘여러 개의 약한 모델(Weak Learners)을 순차적으로 훈련해서, 점점 더 정확한 모델을 만드는 방법’입니다.
즉, 초반의 Decesion Tree의 에러값들을 후반의 Decision Tree들은 수정해 나가는 식으로 학습이 진행됩니다.
AWS에서 정의한 기계 학습에서의 부스팅(boosting)이란 무엇인지 보면서 더 자세하게 말씀드려보겠습니다.
부스팅은 예측 데이터 분석의 오차를 줄이기 위해 기계 학습에 사용되는 방법입니다.
데이터 사이언티스트는 레이블이 지정되지 않은 데이터에 대해 추측하기 위해 레이블이 지정된 데이터에 대한 기계 학습 모델이라고 불리는 기계 학습 소프트웨어를 훈련시킵니다.
단일 기계 학습 모델은 훈련 데이터 집합의 정확도에 따라 예측 오차가 발생할 수 있습니다.
예를 들어 흰색 고양이의 이미지에 대해서만 고양이 식별 모델을 훈련한 경우,
가끔 검은색 고양이를 잘못 식별할 수 있습니다.
부스팅은 여러 모델을 순차적으로 훈련하여 전체 시스템의 정확도를 향상시킴으로써 이 문제를 극복하려고 하는 것입니다.
이러한 문제를 해결하기 위하여 부스팅에서는 '약한 모델 or 학습자(Week Learners)', '강한 모델 or 학습자'라는 개념을 사용하는데요.
이 부분이 어떤 것인지 예시를 통하여 말씀드려보겠습니다.
부스팅은 여러 약한 학습자를 강한 단일 학습 모델로 변환하여 기계 학습의 예측 정확도 및 성능을 개선할 수 있습니다.
기계 학습 모델은 약한 학습자나 강한 학습자일 수 있습니다.
약한 학습자는 무작위 추측과 비슷할 정도로 예측 정확도가 낮습니다.
약한 학습자는 과잉 맞춤에 취약합니다. 즉, 원본 데이터 집합과 너무 많이 다른 데이터는 분류할 수 없습니다.
예를 들어 모델이 뾰족한 귀를 가진 동물인 고양이를 식별하도록 훈련시킨 경우 귀가 말린 고양이는 인식하지 못할 수 있습니다.
강한 학습자는 예측 정확도가 높습니다.
부스팅을 통해 약한 학습자의 시스템을 강한 단일 학습 시스템으로 변환할 수 있습니다.
예를 들어 고양이 이미지를 식별하기 위해서는 뾰족한 귀를 추측하는 약한 학습자와 고양이 눈을 추측하는 또 다른 학습자를 결합해야 합니다.
뾰족한 귀를 지닌 동물 이미지를 분석하면 시스템은 고양이 눈에 대해 다시 한번 분석합니다. 이렇게 하면 시스템의 전체적인 정확도가 개선됩니다.
AWS의 예시가 이해되셨나요?
즉, 부스팅이 왜 필요한지 정리해보자면 아래와 같습니다.
머신러닝 모델 하나만으로 모든 문제를 완벽히 예측하기는 어렵기에
'여러 모델을 조합해서 정확도를 높이자'는 생각이 이전에 포스팅했었던
'앙상블(Ensemble)'기법이고, 그 중 방식 중 하나가 '부스팅(Boosting)' 입니다.
2-2. 부스팅(Boosting) 동작방식
1. 첫 번째 모델을 학습시킵니다.
→ 이 모델은 전체 데이터를 기준으로 예측을 합니다.
2. 이 모델이 틀린 데이터에 주목합니다.
→ 예를 들어, 검은 고양이를 계속 틀렸다면? 다음 모델은 그 부분에 집중합니다.
3. 두 번째 모델을 다시 학습합니다.
→ 이번엔 첫 번째 모델이 틀렸던 데이터를 더 중요하게 생각하며 학습합니다.
4. 이런 식으로 모델을 여러 번 반복적으로 학습하며,
각 모델은 이전 모델의 실수를 보완해나갑니다.
5. 최종 예측은 이 모든 모델의 예측을 조합해서 내립니다.
→ 마치 여러 명의 조언을 종합해서 더 나은 판단을 내리는 것.(앙상블 기법의 특징이죠.)
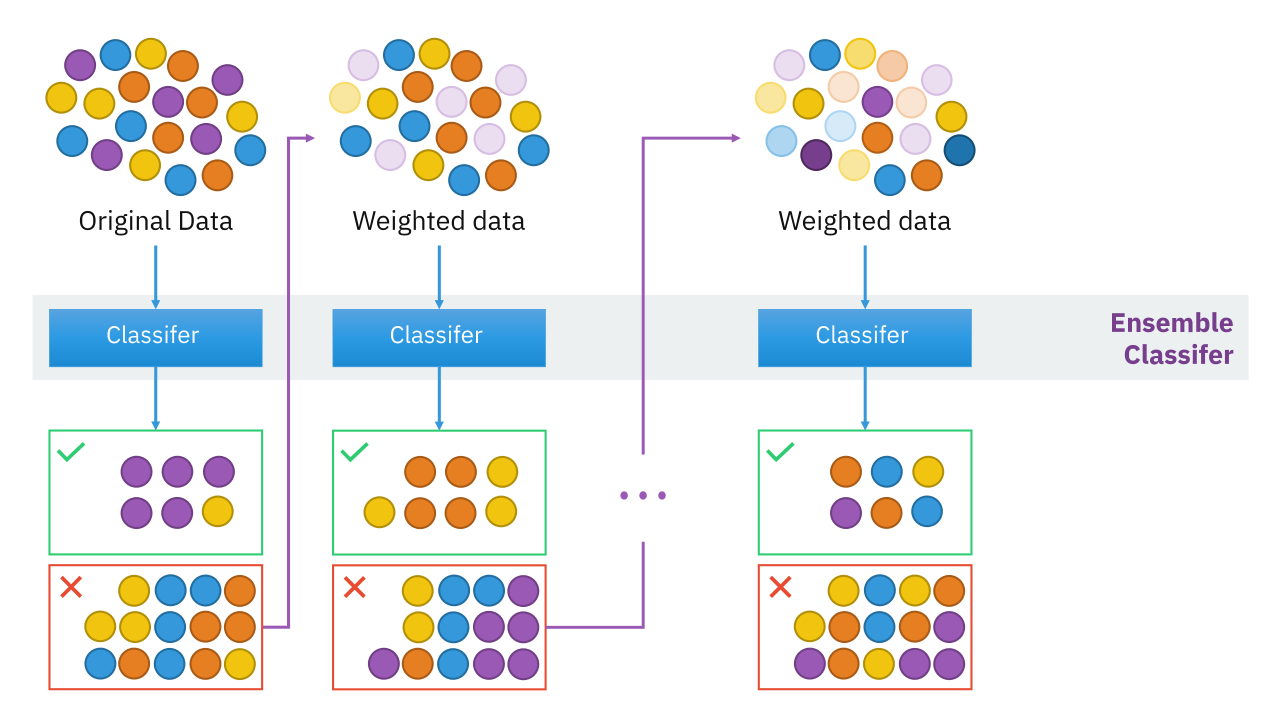
아래 이미지는 AWS에서 Boosting을 설명하는 아키텍쳐 입니다.

그림에 대해서 설명해드리자면
위에서 말씀드렸듯 Boosting의 동작은
'초반의 Decesion Tree의 에러값들을 후반의 Decision Tree들은 수정해 나가는 식으로 학습이 진행됩니다.' 이었습니다.
이 부분을 생각하시고 보시면 더 이해가 잘 되실겁니다.
- (X, Y)라는 데이터셋이 있습니다.
- Tree 1을 먼저 학습합니다 → 이 모델의 예측 결과를 F₁(X)라 합니다.
- F₁(X)의 오차(실제값 Y와 예측값의 차이)를 Residual r₁이라고 합니다.
- 다음 Tree 2는 이 Residual r₁을 학습합니다. 즉, “이전 모델이 못 맞춘 부분”을 예측합니다.
- 이렇게 잔차(residual)를 계속 계산하면서,
- 각 트리의 예측값에 가중치 α를 곱해 전체 예측 모델을 만들어냅니다
이해가 되셨나요??
쉽게 말해 다시한번 말씀드리자면
Boosting은 '초반의 Decesion Tree의 에러값들을 후반의 Decision Tree들은 수정해 나가는 식으로 학습이 진행됩니다'
아키텍쳐에도 나와있듯
- 앞 모델이 틀린 부분 → 다음 모델이 그걸 보완
- 한 모델이 예측한 오차(Residual)를 다음 모델이 학습 데이터로 삼음
- 결과적으로 모델들이 서로 협업하며 점점 정답에 가까워짐
이러한 특징들이 있습니다.
2-3. 부스팅(Boosting)과 배깅 비교
부스팅 및 배깅은 예측 정확도를 개선하는 두 가지 일반적인 앙상블 방법입니다.
이런 학습 방법의 주요 차이점은 훈련 방법입니다.
배깅을 통해 데이터 사이언티스트는 여러 데이터 집합에서 한 번에 여러 약한 학습자를 훈련시켜 약한 학습자의 정확도를 개선합니다.
이와 달리 부스팅은 약한 학습자를 차례로 훈련시킵니다.
쉬운 예시를 들어보자면)
Bagging은 투표(voting)를 통해 결정을 내리는 민주주의입니다.
(이전 포스팅 Bagging 동작 과정 참고)
→ 여러 명(병렬로 학습)이 독립적으로 의견을 내고, 그 평균을 따릅니다.
Boosting은 이전 사람의 의견을 반영하며 점점 더 정교해지는 릴레이 토론입니다.
→ 첫 사람이 한 말을 두 번째 사람이 보완하고, 세 번째는 또 더 정교하게 만듭니다.
좀더 자세하게 말씀드려보자면
2-3-1. Bagging (Bootstrap Aggregating)
- 여러 모델을 병렬로 학습시킵니다. (예: 여러 Decision Tree) (아래 사진 참고)
- 각각의 모델은 서로 다른 데이터 샘플을 가지고 학습합니다. (Bootstrap: 중복 허용 랜덤 샘플링)
- 최종 예측은:
- 분류 문제: 다수결 (Voting)
- 회귀 문제: 평균값 (Averaging)
- 대표 알고리즘: Random Forest

2-3-2. Boosting
- 하나의 모델이 끝난 후, 그 실패/오차를 다음 모델이 보완하면서 순차적으로 학습합니다.
- 앞 모델이 틀린 데이터를 더 중요하게 다뤄서 다음 모델이 잘 맞추도록 합니다.
- 최종 예측은 여러 모델의 예측을 가중 평균 또는 누적합합니다.
- 대표 알고리즘 : Gradient Boosting, XGBoost, LightGBM, CatBoost...
2-4. Gradient란?
GBDT 중 부스팅(Boosting)은 알겠는데
Gradient는 무엇일까?
간단하게 집고 넘어가보자
2-4-1. Gradient란?
gradient란 벡터 공간에서 스칼라 함수의 최대 증가율을 나타내는 벡터 입니다.
기본적으로, gradient는 어떤 점에서 함수의 값이 가장 빠르게 증가하는 방향과 그 증가율을 표시되고,
각 점에서 그래디언트는 이 점을 통과하고 함수의 표면이 가장 가파르게 상승하는 방향을 가리키는 벡터로 정의됩니다.
Gradient Boosting에서의 “Gradient”는 딥러닝에서 말하는 경사하강법(Gradient Descent)의 “Gradient”와 똑같은 의미입니다.
(경사하강법은 비탈길을 따라 내려가듯 손실 함수(Loss Function)가 최소가 되는 지점을 찾는 방법입니다.)
즉, gradient는 머신러닝, 특히 신경망에서 중요한 역할을 하고, 핵심은 아래와 같습니다.
“Gradient” = 오차를 얼마나 줄여야 할지 알려주는 방향
2-4-2. 왜 GBDT에서 Gradient가 등장할까?
Boosting에서는 각 트리가 잔차(residual)를 학습합니다.
그런데 단순한 잔차 대신, 손실 함수(Loss Function)를 줄이는 방향으로 학습하면 더 효율적이겠죠?
그래서 다음 트리는 이전까지의 모델이 만든 예측값에 대해 손실 함수의 기울기(Gradient)를 계산해서,
“이걸 얼마나 어떻게 줄여야 할까?“를 방향성으로 삼아 학습합니다.
예를 들어보자면
- 예측값: 70
- 실제값 : 100
- 오차는 30
- 손실 함수: (100 - 70)² = 900
- 기울기: ∂Loss/∂ŷ = -2(100 - 70) = -60
이 -60이 바로 다음 트리의 학습 목표가 됩니다.
“앞선 모델이 잘못한 부분을 얼마나, 어느 방향으로 고쳐야 할까?“를 알려주는 거죠.
정리해보자면
| 개념 | 설명 |
| Gradient | 손실 함수의 변화량 (오차를 줄이기 위한 방향) |
| Boosting | 이전 모델의 오차를 학습하여 성능을 개선 |
| Garadient Boosting | 오차 대신 손실 함수의 Gradient를 이용하여서 다음 모델을 학습. |
그래서
Gradient Boosting = Gradient(기울기)를 따라 Boosting(오차 보완)하는 방식이 되는 겁니다.
3. GBDT 작동 방식
따라서 GBDT의 전체 동작 방식은 아래와 같습니다.
Gradient → Decision Tree → Boosting
오차의 방향(Gradient)을 계산하고 →
그 오차를 예측하는 트리를 학습(Decision Tree) →
트리들을 순차적으로 연결하여 성능 향상(Boosting)
참고링크
부스팅 알고리즘 (Boosting Algorithm)
부스팅(Boosting) 부스팅은 머신러닝 앙상블 기법 중 하나로 약한 학습기(weak learner)들을 순차적으로 여러개 결합하여 예측 혹은 분류 성능을 높이는 알고리즘이다.
velog.io
https://aws.amazon.com/ko/what-is/boosting/
부스팅이란 무엇인가요? - 기계 학습의 부스팅 설명 - AWS
부스팅은 예측 데이터 분석의 오차를 줄이기 위해 기계 학습에 사용되는 방법입니다. 데이터 사이언티스트는 레이블이 지정되지 않은 데이터에 대해 추측하기 위해 레이블이 지정된 데이터에
aws.amazon.com



