
민프
[Python] ChromeDriver, selenium을 이용하여 크롤링을 해보자 본문
코인 뉴스를 크롤링해서 텔레그램에 보내보려고 한다.
먼저 크롤링이 뭔지 모르겠다면 아래 링크글을 참고하자
https://minf.tistory.com/217
[Python] 크롤링이란 무엇일까?
크롤링이란? https://dict.naver.com/search.dict?dicQuery=Crawling&query=Crawling&target=dic&ie=utf8&query_utf=&isOnlyViewEE= 'Crawling' : 네이버 사전 검색결과 33종 언어사전과 방대한 지식백과를 제공 dict.naver.com 위 사전에
minf.tistory.com
동적 크롤링을 해볼 것 이기에
이 글에서 사용되는 사용되는 라이브러리는 selenium이다
ㅇ. selenium은 뭘까?
Selenium
Selenium automates browsers. That's it!
www.selenium.dev
공식홈페이지에서는
"브라우저를 자동화 합니다. 그게 다야!, 그것으로 무엇을 할지는 전적으로 당신에게 달려있습니다."
라고 나와있다.
Selenium은 2004년에 Jason Huggins의해 만들어졌는데
만들어진 목적이 빈번하게 일어나는 웹 응용 프로그램의 수동적인 테스트가 비효율적이라고 느껴져서 만들어졌다고 한다.
이와같이
Selenium은 주로 웹앱을 테스트하는데 이용하는 프레임워크인데, webdriver라는 API를 통해 운영체제에 설치된 Chrome등의 브라우저를 제어하게 된다.
그럼 이제 설치를 해보고 크롤링을 해보자
먼저 ChromeDriver를 다운받아야하는데
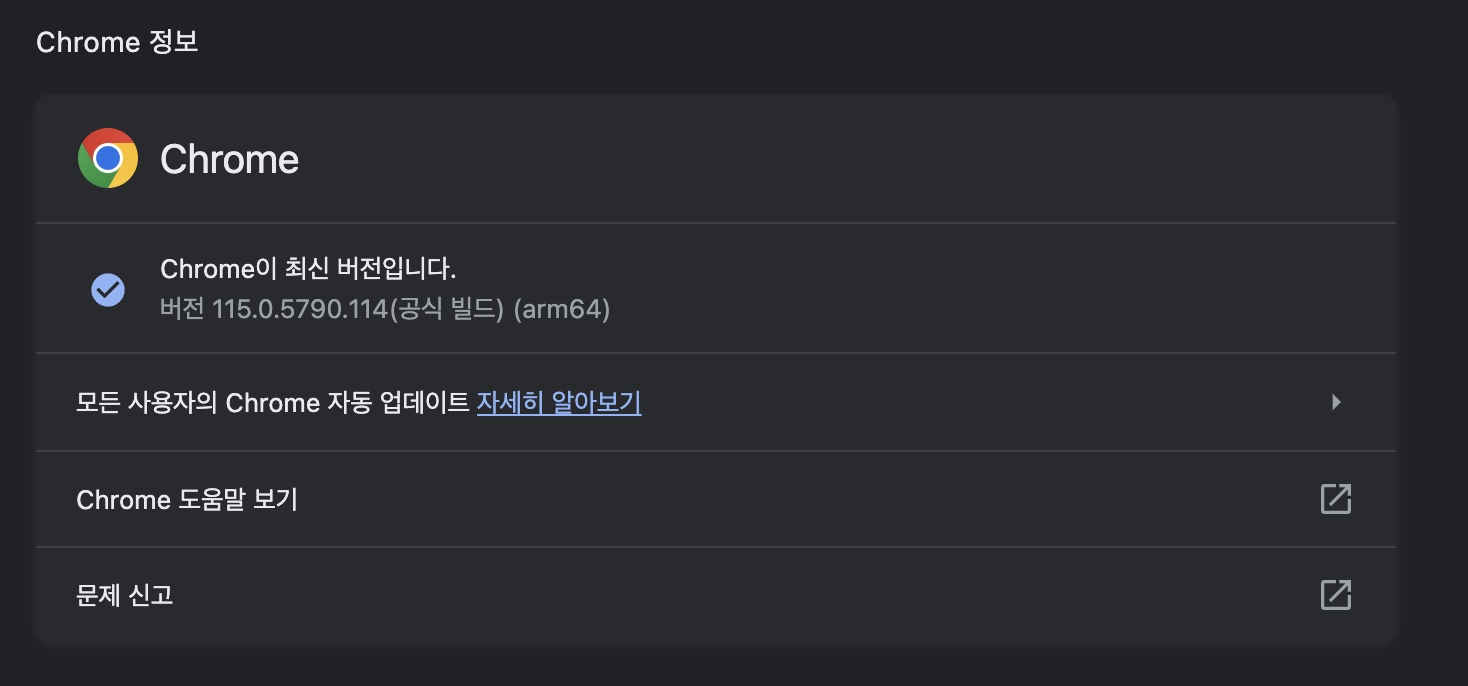
ㅇ. 나의 현재 Chrome 버전을 확인해보자
chrome://settings/help
위 링크를 타고 가면 아래 사진과 같이 현재 나의 Chrome버전을 알 수 있다.
ㅇ. ChromeDriver를 다운받자
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 115 or newer, please consult the Chrome for Testing availability dashboard. This page provides convenient JSON endpoints for specific ChromeDriver version downloading. For older versions of Chrome, please se
chromedriver.chromium.org
위 사이트에서 나의 OS, 버전과 같은 드라이버를 다운받자
ㅇ. Selenium을 설치해보자
pip install selenium
# 혹은
conda install selenium
ChromeDriver와 Selenium을 설치를했다면 준비가 끝난 것 이다.
아래 코드는 coinness의 뉴스룸을 가져와보는 코드이다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# Chrome 드라이버 경로 설정
chromedriver_path = "/usr/local/bin/chromedriver"
options = Options()
options.add_argument('--headless') # 창 숨기기 모드로 실행합니다.
service = Service('/usr/local/bin/chromedriver') # Chrome 드라이버 경로를 지정합니다.
driver = webdriver.Chrome(service=service, options=options) # Chrome 드라이버를 로드합니다.
# 웹 드라이버 초기화
url = 'https://coinness.com/newsroom'
driver.get(url)
# 웹 페이지가 로드되는데 5초를 기다립니다.
time.sleep(10)
# main 태그 내용 가져오기 (xpath로 찾아야 빠르다)
element = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.XPATH, '//*[@id="root"]/div/div[1]/div/main/div[2]/div[1]/button[2]')))
element.click()
# 클릭 후 웹 페이지가 로드되는데 5초를 기다립니다.
time.sleep(5)
# element2 = element.find_elements(By.XPATH, '//*[@id="root"]/div/div[1]/div/main/div[2]/div[3]')
element2 = element.find_elements(By.XPATH, '//*[@id="root"]/div/div[1]/div/main/div[2]/div[3]/a')
print(len(element2))
for news in element2:
print("news.text",news.text)
print("news.text","------")
# print(len(second_div))
# main 태그 내용 가져오기
# main = driver.find_element(By.TAG_NAME, 'main')
# child_divs = main.find_elements(By.TAG_NAME, 'div')
# print("child_divs",child_divs[-1].text)
# for news in child_divs:
# print("news.text",news.text)
# print("news.text","------")
# print("child_divs")
# 하나 값 가져오기
# element = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#root > div > div.sc-fvEvSO.dlSIfT > div > main > div.sc-gXnjX.kGTwrS > div > div.sc-kTxHUi.hBcyRT > div:nth-child(1)')))
# print(element.text)
driver.quit()위 코드를 입력해보면 잘 나오는 것을 확인할 수 있다.
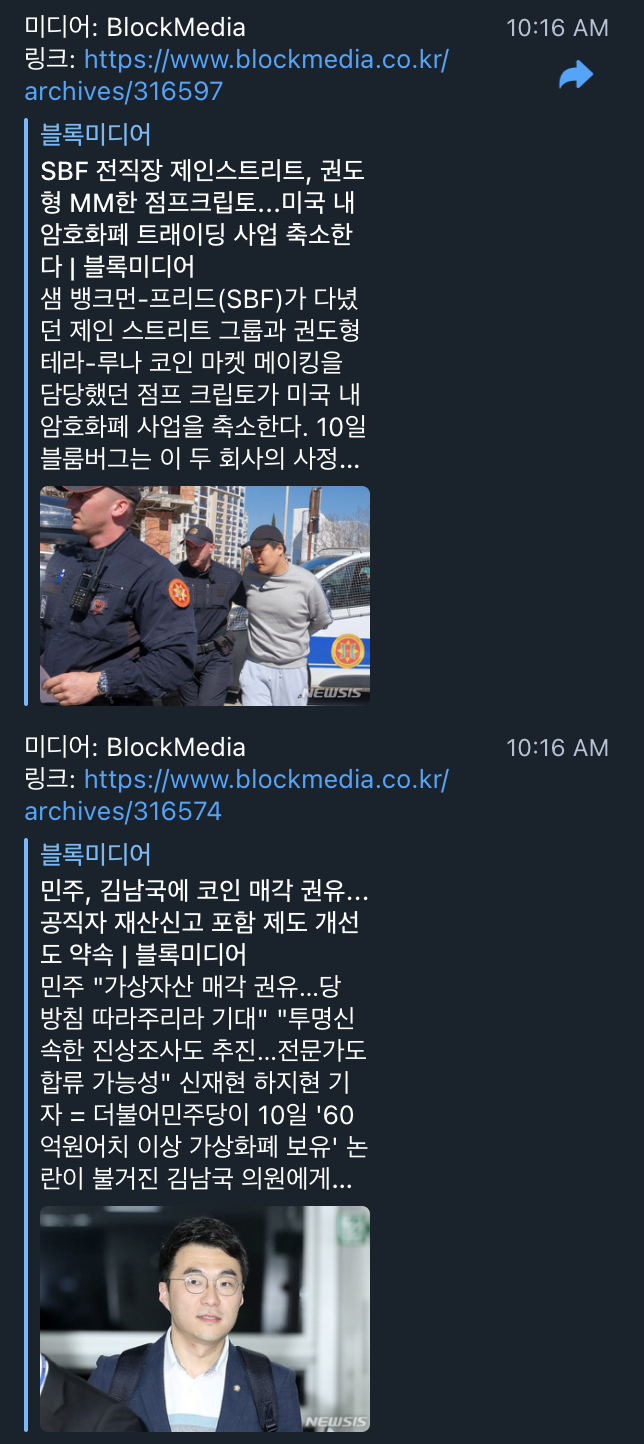
추가로 이것을 이용해서 BlockMedia의 기사들을 크롤링해서 Telegram에도 전송해보았는데, 아래와 같이 잘 나오는 것을 확인할 수 있다.
'인공지능 > [Python]' 카테고리의 다른 글
| [Python] 크롤링이란 무엇일까? (0) | 2023.08.01 |
|---|---|
| [Python] 아나콘다를 설치해보자 (M1 Pro 칩) (0) | 2023.08.01 |
| [Python] 로컬에 있는 아나콘다 가상환경을 EC2 디렉토리에 전송해보자 (0) | 2023.04.19 |
| [Python] 아나콘다 가상환경 공유하기 (export) (0) | 2023.04.19 |
| [Python] talib 라이브러리를 설치해보자 (0) | 2023.04.18 |


